3歳児とグアム旅行
12月20日から23日までの4日間、妻と3歳の息子とグアムに旅行に行ってきたのでその記録をまとめようと思う。 前回の海外旅行日記が オマーン旅行 2024 - しょ〜うぃん広場 なので僕は1年半ぶりの海外旅行である。
事前準備から書こうかと思ったけど、いろいろ書きたいことがあって旅行本編に入るまでに時間がかかりそうなので、まずは旅行の様子を書いていこう。
出国
一人で旅行をしていると出国手続きなんて顔認証の自動ゲートで一瞬なのだが、自動ゲートは135cm以下のこどもは使えないので3歳児がいるとそうはいかない。 海外から来ている旅行者と一緒に入国審査官が対応してくれる長い列に並ばないといけないのでいきなりちょっとしょんぼりする。週末や年末は家族旅行も多いだろうし、そういう時は1列だけでもこども向けの優先列を作ってくれたら嬉しいのになと思ったり。

東京からグアムに直行便があるのはUnitedかJALだけなので、久しぶりにJALに乗ったのだけど、こども向けの機内食がかわいくて良かった。

もっとも、食に興味のない息子が食べるかどうかは別であり、案の定ゼリーとジュース以外は2-3割程しか食べなかった…
タクシー事情
グアムのアントニオ B. ウォン・パット国際空港 (長いので以下、空港) に着いてからは後述する Stroll という配車アプリでホテルまで移動した。タクシーに9分乗って$24(約4000円)で、いきなり物価の高さを突きつけられた。 ただ、こちらで生活してみると大抵のものが日本の2.5倍ぐらいすると分かって、日本のタクシーで10分1500円ぐらいと思えば物価に対しては妥当な値段であったなと後から思った。
グアムでの移動は基本タクシーで何度か配車したのだけど、ToyotaのSienna率がめちゃくちゃ高くて40%ぐらいのタクシーはこの車を使っているような気がした。3回めのSiennaで流石に気になりすぎて運転手に聞いたら、ハイブリッドで燃費がいいかららしい。なるほど、確かにタクシーに燃費は命だ。
そして、タクシーの運転手はなぜか現地出身の方が全然いない。5回乗って多分1度だけ現地の人だった。皆英語は流暢ではなくて、うち2人はたぶん韓国出身な感じがした。というのは旅行者の内訳が感覚的に80%韓国人、15%日本人、残り5%その他という具合なので、まぁそういうことなのだろう。現地の人は使わないしね。
最後に乗ったタクシーの運転手が今年10月に東京に行った、来月は大阪に行くよ!と言っていて、おぉタクシー運転手でもそんなに頻繁に日本に旅行に行けるぐらい稼いでいるのかと驚いたけど、ここは2.5倍物価の高い場所であって、日本円で換算すればきっと年収は1000-1200万円ぐらいにはなるだろうから"安い"日本に行くのなんて確かに簡単である。(日本最高だけどご飯は少ないよね!!って言ってたのでキミ達が食べ過ぎだよ!って返しといた)
空港からホテルに移動する間に運転手が、このマリオットホテルはコロナで潰れた、あっちの免税店が集まっているモールも高級ブランド店がたくさん閉店した、と教えてくれ、たしかに観光に収入を依存している地域はコロナは大変だっただろうなぁ。
どこの国に行ってもそうだけど、現地のことをよく知っていて一番会話する機会があるのがタクシー運転手なので、今回もおもしろいことをたくさん聞けたし、ぜひ日本のタクシー運転手も簡単な英語が話せるようになって旅行者にいろいろ教えてあげてほしいと切に思う。
ホテル
そんなこんなで今回のホテル Dusit Beach Resort Guam に着いた。ホテル選びは妻に任せたので特に書くことはないのだけど、ホテル内にプールもあるし、ビーチへも直接アクセスできるし、不満はなく良いホテルだった。3泊4日朝食付きで約$1000(16万円)だった。
このホテルがあるTumonが観光者向けの中心地という感じで、歩いて行ける距離にスーパーもレストランも数多くあって便利だった。こどもがいると長距離移動は面倒なので助かる。
ただでさえそんなに大きな島でないグアムだけれども今回は空港とこの赤丸の中だけで生活していて、グアムに行ったけどグアムのことを何も分かっていない感じがする。。。 まぁバカンスなのでこれでよいのだ。

ホテルからの眺めはこんな感じ。


曇りの方が海がエメラルドグリーン(?)に見えるのは面白い。カメラの問題?
あ、ホテルの不満一つあった。
テレビのチャンネルが豊富で、NHKもCCTV(中国)もアメリカのチャンネルもたくさん見れるのだけど、受信が不安定なのかそもそも放送されていないのかよくわからないが、NHK Internationalが初日しか映らなくてこどもの機嫌が悪くなって大変だった笑。
1チャンネルがNHKで日本語で普通の日本のNHKが流れていて、2チャンネルはNHK Internationalというニュースは英語圏向けの特別番組で、ニュース以外の時間はEテレのコンテンツを英語吹き替えで放送しているチャンネルがあった。初日は夕飯後寝る前までNHK Internationalを見ていて、それがお気に入りだったようで、2日目も3日目も「2チャンネルにして!」と言うのだけど、映らなくて画面真っ黒で、昨日まで映っていたのに突然見えなくなるのは納得いかないらしく「これじゃないぃぃぃ!2チャンネルぅうううう!!」「いや、これが2チャンネルだって、今日はおやすみなんじゃない?」「違うよぉぉ!これ2チャンネルじゃないよぉぉぉぉぉおお」と泣き叫んでいた。
プールとビーチ
プールは専用のバスタオルと自動空気入れがあって便利だった。大きな浮き輪を持っていったので空気入れがなかったときのために自分たちで持っていくか悩んだけど、持っていかなくて良かった。(他の人のブログを読んでありそうな感じはしていたけど)
プールサイドのリクライニングチェアもそこそこ数があってゆったりと過ごせる。ただ、問題は天気で、乾季の12月に行っても半日ぐらい晴れ、半日は雨+強風みたいなことが多くて、27℃の中で雨に降られて冷水のプールで遊ぶのは普通に風邪ひきそうになるレベルなので注意が必要。
確かに月間降水量を見ると、乾季の12月でも実は東京の4月5月ぐらいの雨は降るらしい。(タクシーの運ちゃんも島の天気はいつも不安定だよって言ってた)

南国のゆったりした天候の下で好きなときにプール行ったり海行ったりできるかなと勝手に想像していたので、晴れのタイミングを見計らって行かないといけないのはスケジュールを組むのが少し大変だった。
ちなみに、ホテルのシャワーは19:00-20:00ぐらいのピークタイム(?)に入ると、給湯器の出力が足りていなくて38℃ぐらいのぬるま湯で入ることになるが、昼間であれば42-43℃ぐらいの温度まできちんと出るので、プールで冷え切った身体を温めることはできる。バスタブあって神。
ビーチの砂は細かくサラサラで触っていて気持ちが良い。少し掘れば湿った砂が出てくるので山も簡単に作れる!


夕飯前に少し時間潰す必要があったときに、Geminiに3歳児も楽しめるおすすめのスケジュール考えて!って頼んだら、こどもであればビーチで走ったり砂遊びすると楽しいでしょうって返事してきて、ホントか!?って疑ってたんだけど、帰りに何が一番楽しかったと息子に聞いたら「ビーチの砂遊び!」って返ってきてマジか…ってなった。
ショッピングモールで1時間も巨大ピタゴラスイッチ装置見てたくせに…

Village of Donki
空港から車で4分ぐらいのところにドン・キホーテのグアム版があって、帰りの飛行機までの時間調整に便利だった。 中にはフードコートもあるのでお土産買いながらご飯も食べてゆっくりできるし、スーツケースを預かってくれるサービスもある。
現地スタッフが「コレ オミヤゲ 二 イイヨ。カイシャ デ バラマキ デキルヨ」って小袋に入ったお菓子の試食を提供しながら説明してて、セールストークのレベル高いなと笑ってしまった。

Sakuraって書いてあるから多分日本米に近い(けど日本産ではない)種類なんだろうけど、22kgで6000円は安い… (ってか22kgの米を買って持って帰れるのが物理的に強い…)

フードコートにポケモンカードのブースが催事で来てきて、こどもの時間潰しにと思って2パック買ってみたらなんかニンフィアのキラキラしたやつ当たって喜んでた。(1パック10枚で$8)
え、もしかして高く売れるやつ!?と思ってGeminiに聞いたら数百円ぐらいの普通のカードだった。最近のカードってキラキラ度合いもインフレしてるのね。

帰国
3泊4日で、実滞在時間はまるまる3日分ぐらいだったけど、これぐらいでちょうど良かったなという感じ。これ以上長くいるならもう少し行動範囲を広げないといけないけれど、行きたい先は大人がやりたいものであって3歳児に新しいアクティビティを提供できる感じがしない。 海とプールだけなら沖縄でいいじゃん!ってなるけど、それはそう。
今回はこどもが英語教室に通っているものあって、実際の英語環境を見せたかったというのが一番の理由なのでまぁそれは達成できたかな。ホテルでもレストランでも"スタッフは"英語を喋っていて「Thank you!」「Bye bye」は話す機会があるし、ホテルの朝食でたまたま隣が(多分)米国人の家族になって同じ3歳のこどもに「Hello~」とこちらから話しかけることもできたから十分かな。
日本から近くて英語を話している国となると、フィリピンかグアム/サイパンでその次がハワイ、オーストラリアになって、5時間超えのフライトはちょっとつらいなーという気持ちになるので、3,4時間のフライトで行けて治安も良くて英語が話されているグアムは良い選択肢になる。
ただやることはあまりないので、もし次にまた来るとしたらこどもが小中学生になって英検3級とか準2級とか取れたご褒美に、という感じかな。 個人的に行きたかったけど行けなかった太平洋戦争記念館はまたその時に。


事前準備
ということで最初にスキップした事前準備編をこのあたりで。グアムに行く予定がない人はスキップしてもらって大丈夫。
ESTAじゃなくてグアム専用のビザG-CNMI ETAが無料である
これ最初知らなくて普通に一人2000円ぐらい払ってESTAを取ってしまったのだけど、グアムとサイパンに行くのであればG-CNMI ETAという別の観光ビザがあってこちらは無料で取得できるのでこちらの方がおすすめ。
グアムに中国人観光客が全然いないのは両国仲が悪くて観光ビザの取得が難しいからだと想像していたんだけど、今調べてみたらG-CNMI ETAは中国人でも比較的簡単に取得できるそうなので、中国人が全くいなかったのは謎なままになってしまった。
Strollのインストール
タクシーの配車アプリ。流しのタクシーは使っていないのでそれとの比較はできないのだけど、リクエストして5分ぐらいで来るのと、事前に料金がわかるので便利。あとセダンかSUVかも選べるので、荷物が多い時に大きな車を手配したいときにも嬉しい。
ただ前のお客さんを乗せている時にも次の客を取れる仕組みのようで、ドライバーは出発してから頻繁にスマホ触って次の客とテキストメッセージしているので、到着に少し時間がかかるのと、普通に運転の様子を見ていてこっちが怖くなるというデメリットがある。
アプリのインストール後にメールか電話番号のSMS認証が必要なので、日本でインストールしておくのが安心だと思う。SMSは即時来たけど、メールは2時間後ぐらいに認証コードのメールが届いて困った。
スマホの通信網確保
最近はスマホ側もプロバイダ側もeSIMに対応していることが多いので、物理SIMを入れ替えていた時代と比べればめちゃくちゃ楽になった。 が今回は僕は(普段UQモバイルを使っているので)au海外放題を使うことにした。妻は普段ahamoなので追加料金なしで普通に使える。
au海外放題は24時間1000円ぐらいなので、物価の高い国でSIM買っても同じぐらいだなと思って4000円払った。もう少し長くいるのであれば多分現地のプロバイダ使った方が安い気がする。(安くなっても1000~2000円なのでちゃんと調べてない)
スーツケース
水着、浮き輪を持っていくといきなり荷物が増える。。 僕が荷物少ない方で、妻は多分女性の平均ぐらいで、こども1人で、80Lスーツケース、60Lボストンバッグ(背負えるタイプ)、15Lぐらいのスーツケースの上に載せられる小さなバッグ、の3つで少し余裕があるかなぐらいだった。(あと大人の手荷物バッグね)
お土産たくさん買って帰りたい場合は帰りはこれでは入らなくなると思う。 一般的には1人1日10Lぐらいなので、半袖で過ごせる国に行くにしては大荷物…
そしてそれに加えてベビーカーも… (こどもよ、歩いてくれ)
空港の駐車場予約
グアムに限った話ではないけれど、空港の駐車場を予約しておくと繁忙期でも安心して車停められるので便利だよ。 成田は1400円でできるよ。
パスポートの電子申請は大変
これはただの愚痴。パスポートは2025年3月のオンライン申請ができるようになってすぐに更新/取得したのだけど、入力ミスがあった時になにが問題なのか説明がわかりにくい & 修正の結果が分かるのが1週間後というので、フィードバックループが遅くて結局手に入れるまで1ヶ月半ぐらいかかってしまった。
自分はパスポートの更新だと思って"更新"を選択して進めたのだけど、前回の取得時から本籍地が変わっていた影響で実は新規申し込みを選ばないと行けなかったらしい。そもそもそれぐらいなら受け付けた側で新規申し込み扱いにしてくれYo!という感じだし、「本籍地が変わっているので新規申し込みしてください」の一言あるだけでわかるのに「棄却理由: 本籍地不一致のため更新不可」みたいなテンプレの棄却理由から1つ選びましたみたいな、次にどう修正したらいいのかわからない理由で棄却されて、結局3回目でやっと通った。(これだけで半月ぐらいかかった…)
ので、急いでいる人は従来通りにパスポートセンターに行って対面で申し込むのが安心だと思う。
おまけ
スパムむすびのご飯と具のバランス…と思って思わず撮ってしまった。総量を大きくしないといけないから頑張ってお米増やしました的な背景を感じる。

息子は飛行機の翼がぴよってなっているのが印象に残っていたらしくて、ホテルでテイクアウトの夕飯食べながらもピヨってしてた。
「飛行機はね~ ここがねー、ぴよぴよぴよぴよ~ってしてんだよ~ ぐはははあぁ」って笑ってて楽しそうだった。(そんなに何度もカクカクはしてないぞ)

今日朝起きてからグアムの旅行日記書いててさ~って朝ごはんを食べながら妻と話していたら「えっ!早く読みた~い!」って言われて、ブログ楽しみにしてくれてるの嬉しいなと思いながらも、僕はそんなに素直ではないので「いや、自分も一緒に行ったやんけぇ!」ってツッコんどいた。
おしまい。
ディズニーシー ファンタジースプリングスにオープン2日目に行ってきた
6月6日に正式オープンしたディズニーシーの新エリアファンタジースプリングスにオープン2日目の6月7日(金)に行ってきたのでそのレポート。
心の広い妻のおかげで、1日子育てを任せて朝から晩まで自由な時間を手に入れることができ、思う存分1人ティズ二ーを楽しめたのでその記録。事前準備から当日の行動、ファンタジースプリングスの総評を書いていこうと思う。
私はディズニーは好きだが行く前にいろいろと調べるぐらいで、何年もずっと情報を追いかけているDオタではないので、一部誤った情報があるかもしれないがそれは容赦してほしい。
事前準備
ディズニーに限らず、旅行全般に当てはまるが下調べの時間がやはり一番楽しい。特に自分はアトラクションを楽しみたい勢なので、いかに効率よくアトラクションを回れるか、どういう立ち回りをしたら新エリアを楽しむためのDPA(Disney Premier Access, 有料チケット)やSP(Standby Pass, 無料チケット)を取れるかを考えている時間が至高だった。 ディズニーと一般的な旅行の違いは、ディズニーは当日にならないと混み具合やアトラクションの待ち時間がわからないので、事前に最適なルートを決められないことである。つまり事前に知識を頭に叩き込んでおいて、その知識を持って当日の状況に合わせて臨機応変に計画を変えて行動する必要がある。最適化オタクとしては最高のゲームである。(大袈裟)
ディズニーは新アトラクションや新エリアの正式オープンの2-3週間前からスニークと呼ばれるプレオープン期間があるので、実は正式オープンの6月6日より前にも新エリアを体験している人たちはたくさんいる。運営側もオープン前にオペレーションの確認などをしたいのだろう。アトラクションが異常検知してシステム調整になってしまってもゲストも、スニーク期間だったら許せるか…という気持ちにもなる。そのスニークの様子は「ファンタジースプリングス スニーク」などのキーワードでYouTubeやXで検索するとそこそこ情報がでてきて、朝何時ぐらいから並べばDPAが買えるとか、朝買えなくてもアプリをずっとリロードしていればキャンセルされたSPが拾えるとかいろいろと分かる。
Xの #tdr_now のハッシュタグも朝の混雑具合の確認のために毎朝見ていた。(余談だけれども、有名なハッシュタグはインプレッション稼ぎのために海外アカウントが全く関係ないことを連投していて、ハッシュタグのタイムラインが汚染されているので、欲しい情報を探すのには結構苦労する。)
情報収集の結果わかっていた事としては
- 普通の1デイチケットでは新エリアのアトラクションのDPAかSPがないと新エリアには入れない
- 正式な開園時間は9:00だが、8:15に開園する (ディズニーのホテルに泊まっている人はその15分前や30分前に入れる権利がある)
- DPAは8:17~8:23ぐらいに売り切れる
- SPはアトラクションによって差はあるが8:50やそれ以降まで残っているので、1つは確実に取れそう
ということ。DPAとSPを簡単に説明すると、DPAは有料のチケットで(1500-2000円/1回)で乗り場まで5分前後たどり着けるもので、SPは無料のチケットで普通の待ち列に並ぶことができる権利を得られるもの。いずれも1時間の枠が指定されるので、その時間の間にアトラクションのところに行く必要がある。2枚目のDPAやSPを発行するには、1枚目で指定された時間を過ぎるか、チケット発行からそれぞれ60分か120分過ぎる必要がある。 分かると思うが、とにかくルールがややこしい。簡単に言えば、どちらのチケットも先着順で開園後すぐに売り切れるので、DPAが売り切れる前にインパークできればDPAとSPで合わせて2つのアトラクションに乗れるし、DPAが買えなかったらSPで1つのアトラクションしか乗れないと考えれば良い。
つまり勝負は8:15の開園後2-3分以内にパークの中に入って、操作ミスなくディズニーのモバイルアプリでDPAを買えるかどうかというところにある。

勝負に勝つために
YouTubeでスニーク時期の朝の混雑ぐらいを調べた感じ、ディズニーリゾートライン(以下、リゾラ)が走り始める6:30頃からは一気に人が増え始めるので、その前には確実に着いていたい。 舞浜駅からディズニーシーにリゾラを使わずに行ったことがなかったのだが、調べると駅から徒歩15分でディズニーシーに着けるらしい。
私は関東に住んでおり、最寄り駅を始発で出ると6:07に舞浜駅着になるのでリゾラ始発前には着けそうである。(移動時間を考えるとエントランスに6:23分頃着になるか)
とはいえ開園後3-4分以内に入るにはかなり前の方に並んでいる必要があり、6:23ではちょっと心もとない。(車で来る勢は4:30ぐらいに駐車場が開くので彼らにはどう考えても勝てず、無視することにする) どうにかもう少し早く着く方法はないかと考えていると新木場駅での乗り換えを2分でいければもう一本前の電車に乗れて5:50に舞浜駅に着けることがわかった。ただ、鉄道運行会社を跨いでの乗り換えなので改札口を一度出る必要があり、2分での乗り換えは厳しそうである。実際にルート検索のサービスを使って、検索条件の"乗換時間"を"急いで"にしてもこの2分間での乗り換えルートは出てこない。が、この17分は大きいのでどうしてもこれに乗りたい。
便利な時代になってYouTubeで調べれば乗り換えの最短ルートが映像で出てくる。何号車の何番のドアから出れば一番近いエスカレーターの目の前で降りれるのか等メモして2分間の乗り換えに備えた。その撮影者によると降車してから乗り換え先のホームまで徒歩で1分57秒ほどかかったそう。

当日
小さな子どもが家にいると便利なもので、大人も夜は21時前には寝る習慣ができているので、翌朝4時起きのために21時に寝ることも容易い御用である。問題は興奮のあまり2時間毎に目が覚めてしまったことだが、それでも7時間は寝れたので体力は十分に回復した。
問題の新木場駅の乗り換えは入念なイメトレの成果で、降車から乗り換え先のホームまで45秒で移動できた。私と同じことを考えている人が多く、ダッシュしている人たちがそこそこいた。Suicaタッチのためだけに利き腕の右手に着けているApple Watchは、改札で少し反応が遅いときがあるのだが、反応するまで1.5秒ぐらいかざしていたら、うしろのおじさんに「おいっ!!」って怒鳴られた。こわい。
とにかく無事に5:50に舞浜駅に着いて、6:05にエントランスについて並び始めた。
6:05時点でサウス植木1列目終わりぐらい。
— showwin (@showwin) June 6, 2024
2列目以降かなと思ってたから、思ったよりも前に来れた。これはDPA狙える説。#ディズニーシー#ファンタジースプリングス#tdr_now pic.twitter.com/XUMx3hvsil
この前日のオープン初日はこの時間で2倍以上の列だったような記憶があるので、2日目はそれと比べるとだいぶ"ガチ勢"は減った模様。 それでも前に50人ぐらい並んでいたので、1人通過に5秒かかるとして約4分。オープン初日のDPAが8:17に全部売り切れていたので、ちょっと厳しいかもしれないが、ここまで来たら後は祈るしかない。
6時に着いて8時過ぎの開園まで2時間もなにしてるの?と思われるかもしれないが、この2時間はあっという間に過ぎる。電車に乗る前にコンビニで買った朝ご飯を食べたり、DPAを最速で買うためにディズニーアプリの操作の練習をしたり、周りのカップルの話を盗み聞きしたり、朝ワンオペで頑張っている妻と子にビデオ通話で家族サービスをしたりと、やることは尽きない。
ちなみに7時少し過ぎた頃に、座り込みをやめて立って並んでくださいと案内される。特にひとりディズニー勢は立たされてしまうと列に戻ることが難しいので、7時より前にレジャーシート等で場所を確保したままお手洗いに行っておくことをオススメする。
開園時間は予想通り8:15だった。その場合大体10分前ぐらいの8:05から手荷物検査が始まる。手荷物も服装も金属探知機に引っかからないように考慮したので、追加検査に引っかかることなく、ここで7人ぐらい抜かした。手荷物検査のプロセスは二重になっていて、初回の簡易金属探知機に引っかかるとカバンを開けて確認するレーンに案内される。そちらにいくと確認作業の間どんどん抜かれていくので、金属類はなるべく持っていかないことが望ましい。ベルトのバックルとか注意。モバイルバッテリーは大丈夫だった。
ここまでは順調だったのだが、インパーク直前のゲートで前の人が手間取っており列が進まなくなってしまった。慌ててスマホを触っていたのでチケットを画面に表示させておくのを忘れていたのだろうか。1分ぐらい経っても全然進まないので、隣の列に移るかどうか判断を迫られた。開園直後はどの列も高密度状態なので横から入るのも難しく、結局列が動くまで大人しく待っていたのだが、この影響で2分ぐらい遅れたと思う。
手荷物検査分のアドバンテージを考えても結果的には期待値よりは遅いであろう8:20のインパークとなってしまったが、無事に8:21にピーターパン DPA 13:20~14:20とアナ雪 SP 12:45-13:45 を確保することができた。大勝利。
DPA購入時の注意点としては、過去にスマホのディズニーアプリで決済をしたことがない場合、クレカの新規登録が必要になることである。パークチケットをオンラインで買ったとしてもその時に登録したクレカはスマホのディズニーアプリでは登録されていないので気をつけたい。DPAの枠を選択した後にクレカの番号入力画面に遷移するので、クレカの番号入力に時間がかかってもDPA自体は買えると思うが、その後のSPの取得が遅れてしまうので、最速で操作したい方はクリップボードに事前にクレカの番号をコピーしておき、使用期限とセキュリティコードは頭で覚えておくことをオススメする。
初日は8:17にすべてのDPAが売り切れていたことを考えれば、2日目の競争率は低かったようだ。
【6月6日(木)TDSファンタジースプリングス】
— Disney Colors - クロロ (@DisneyColorsJp) June 6, 2024
DPAはハッピーエントリー(ホテルアーリー)じゃないと厳しそう!
一般入園だと徹夜組で終わり、スマホ操作ひとつミスれば取れない世界…
スタンバイパスもアナ雪は瞬殺
ティンカーベルは午後のみで発行数が少なそう
ピーターとラプは一般入園でも取れそう pic.twitter.com/8pRpUGsAA4
とはいえこの日も私が買った5分後にはDPAはすべて売り切れていた。
【6月7日(金)TDSファンタジースプリングス】
— Disney Colors - クロロ (@DisneyColorsJp) June 7, 2024
昨日と違って6時台から開園待ちで何かしらDPAが取れそう!
スタンバイパスは8時前着でアナ雪も可能性あり。ピーターとラプは2つめ取得できる時間帯で一気に無くなるかんじ
明らかに昨日より発行数が増えた印象です!
この傾向が続くなら平日は余裕そう? pic.twitter.com/nyqJ1U4SJs
朝のDPA, SP争奪戦さえ終わってしまえばあとは消化試合なので、気楽にディズニーシーを楽しむだけ。
ちなみにファンタジースプリングスがオープンしてからはディズニーシー自体は結構空いていて、従来のアトラクションもかなり少ない待ち時間で乗ることができる。
私はいつも ディズニーランド ディズニーシー 混雑予想カレンダー というサイトの過去の待ち時間を見ていつどれぐらい混雑していたかを確認しているのだが、見て分かるようにオープンの6月6日からかなり空いている。


各アトラクションが具体的にどれぐらいの待ち時間かというとこんな感じ。

普段から見ている人でないとこれがどれぐらい空いているのかわかりにくいかも知れないがソアリンが平均50分ぐらいで乗れるのは異常である。(ちなみに私は35分待ちで乗った)
新エリアが増えたことで同じ入場人数でも待ち時間が減っているのでは?とも思うかもしれないが、うえのカレンダー上でスニークをやっていた28日〜2日よりも空いているのでそういうことである。
参考までにインパークしてからのタイムラインを乗せておく。こういうの興味ない人はスキップしていただけたら。
- 8:20 インパーク
- 8:21 ピーターパンDPA取得 13:20-14:20
- 8:21 アナ雪 SP取得 12:45-13:45
- 8:22 ダックリング モバイルオーダー 12:40-12:50
- 8:22 ニモ PP(Priority Pass)取得 9:05 - 10:05
- 8:25 BBB取得 17:15- (ジャンボリミッキー売り切れ)
- 8:28 センター 20分待ち
- 9:00 2万マイル 10分待ち (8:50でセンター60分待ちだったので諦め)
- 9:25 ニモ with PP 15分待ち (結局スタンバイパスと変わらない列に流された)
- 9:25 タートルトークPP取得 9:55-10:55
- 9:50 エレクトリックレイルウェイ
- 9:55 トイマニ 35分待ち
- 10:21 ラプンツェルSP取得 17:10-18:10 (初回SP取得から120分経過のため2枚目のSP取得可能)
- 10:40 タートルトーク 15分待ち PP使っても使わなくても一緒 (目の前で締め切りになってしまって15分待つことになったの悲しい)
- 11:15 ジャンボリミッキー 外から鑑賞
- 11:25 タワテラ 30分待ち
- 12:10 移動しながらギョウザドッグ購入
- 12:22 インディ シングルライダー 3分待ち
- 12:35-42 7分間ひたすらリロードでキャンセル拾い成功 4回画面に出てきたけど取れたの最後だけ ピーターパン SP取得 13:40-14:40
- 12:45 アナ雪 45分待ち
- (ダックリングにここで行きたがったが昼ご飯食べていたらDPA ~14:20に間に合わないので諦め)
- 13:45 ピーターパン DPA 10-15分待ち
- ファンスプ散歩しながらルックアウトのモバイルオーダー
- 14:20 ピーターパン SP 20分待ち
- 14:45 レイジング シングル 2分待ち
- 14:55 マジックランプ 20分待ち
- 15:35 ファンスプ 2回目イン
- 15:40 ルックアウト フード受け取り
- 16:15 ソアリン 35分待ち (パレード中なので空いてる)
- 17:10 マーメイドラグーンで子どもへのお土産購入
- 17:35 ラプンツェル SP 35分待ち (実際25分)
- (17:45-18:10 ビッグバンドビート捨て)
- 18:10 レイジング シングル 3分待ち
- 18:23 インディ シングル 2分待ち
- 18:40 子どもへのお土産購入
- 18:45 ドックサイドダイナーで夕飯
- 19:10 ニューヨーク・デリでデザート
- 19:15-20:00 ビリーヴ!~シー・オブ・ドリームス 鑑賞 (ちょっと早めに抜け)
- 20:00 タワテラ15分待ち
- 20:25 タワテラ 25分待ち
- 21:05 タワテラ終了帰宅
結果SPが結構遅くまで残っていたことと、キャンセル拾いもできたので、新アトラクション4種類のうち3種類に計4回乗れた。どのアトラクションも1回乗ったら満足かなというクオリティだったのでこれで新エリアは遊び尽くした感はある。
記録からも分かるようにだいたい待ち時間は15-25分ぐらいなので、このタイムラインをメモしながら、次はどのアトラクションに行くかなーと考えていると、大体乗り場まで着いてしまう。ひとりでアトラクション並ぶのは暇すぎるかなと思って普段聞いているポッドキャストを溜め込んでおいたが、一度も聞くことはなかった。
気づき
今回は入念に下調べをしたこともあって気付いたこと、学んだことは多かった。種類別に書いてみる。
ファンタジースプリングス
- 新エリアはディズニーシーらしく"水"が至る所にあって良い



- 新エリアに入場できる回数が公式ホームページを見てもわかりにくかったが、アプリのチケット部分を見るとあと何回入れるのかわかりやすい

- アナ雪は待ち列の作り込みがしっかりしているのでDPAよりもSPで普通に並んだ方が満足度が高い、という事前情報は確かに同意。乗り場まで30分ぐらいのところになると室内で空調が効いているので快適。


- 先にも書いた通り、普通の1デイパスで乗れる範囲で満足したので、新エリア内無限DPAの効果があるファンタジースプリングス・マジックパスは今後買うことはなさそう。(購入にはホテル宿泊が必須なので、関東住みの人にはあまり嬉しくないという理由もある)
- 2024年オープンのアトラクションにしてはちょっと物足りない感じがした。ピーターパンはUSJのスパイダーマン(1999年開業)と大差ないレベルだし、アナ雪も少しギミックはあるもののほぼ普通のボート型アトラクション。いずれも2016年開業の上海ディズニーランドのカリブの海賊のクオリティには全然及ばない感じがする。(比較するものでもないかもしれないけど、あのカリブの海賊は10回以上乗りたいと思うアトラクションだった)
- 多くの人が言っているがフードのクオリティは値段に釣り合っていない。


- DPAかSP (かマジックバス)がないと新エリアに入れない制限に対して批判を想定していた(?)のか、入場制限の手前に映えスポットがあってディズニーの優しさを感じた

ディズニーシー全般
- これぐらいの混雑度だとPriority Passの意味は殆どなく、普通のスタンバイの列と同じところに通される
- インディジョーンズとレイジングスピリッツのPriority Passは途中から普通の列と合流するので、ひとりの場合はシングルライダーで乗るほうが早い
- 観覧にチケットが必要なショーは抽選ではなくて、先着順。新エリアの情報収集ばかりしていたため、ルールをきちんと理解しておらず、インパーク直後に取得しなかったのでジャンボリミッキーを逃してしまった… (前に来たときは抽選だった気がするな)
- パーク内で聞こえてくる声の1-2割は非日本語で、そのうち7割が中国語、2割が韓国語、1割が英語という感じだった。去年(これもひとりで)行ったUSJよりも日本人率は高い気がする。
混雑・立ち回り
- オープン直後はガチ勢(Dオタ)が来ると思われがちのため(?)意外と空いていた。これは私も事前に予想していて、ガチ勢はスニークの期間に行っている and 彼らは初日が大事なので、2日目以降はそれほど来ない and 一般人は開園直後ということで混雑を予想して来ない、ということで2日目はかなり好条件なのではと考えていたがその通りだった。実際に今週から徐々に混み出している。
- 公式の開園時間前はアプリ上では待ち時間が見れないので9時以前の待ち時間がどれぐらいなのか知見がなかったが、ハッピーエントリー勢が先に入っているためだいたい既に20-40分待ちぐらいになっている。9時前に2つ乗ることは難しそう。(初手ソアリンはスキップしたが、30分待ちと案内されていた)
- これぐらいの空き具合で、長時間休憩も取らずに歩き続けると1日で27000歩歩くことになる。直近1年の1日歩数平均の7倍ぐらい歩いていて流石に帰る時は足が痛かった。
- 舞浜駅とディズニーシー間の徒歩15分は意外と距離があるので、気合をいれて速歩きでずっと歩き続けると気温20度でも朝から汗をかくので注意。最速で歩き続けなくても軽く速歩きするぐらいでも結果インパークの時間はほとんど変わらなかったかなと思う。
まとめ
まだまだ情報が少ない中で事前にできるだけ情報収集して、最善の手を探して行動するというのはやはり楽しい。いつもは似たようなことをモニターの前に座ってゲームの中でやっているのだが、たまには自分の身体を使って現実世界でそれをやるのも良いなと思った。
今回で下調べは十分にできたので、涼しくなってきた頃に今度は家族みんなで行くぞ!

オマーン旅行 2024
2024年のゴールデンウィーク前半はオマーンの首都マスカットに旅行に行ってきたのでその旅の記録を書く。 GWに妻が子どもを実家に連れて帰るとのことで、5日間の自由時間が手に入ったので、ここぞとばかりに海外旅行行きを決めた。
なぜオマーン
5日しかなく、複数国を回るような旅行は向いていないので、単発で興味がある国を選ぶことにした。悲しいことに、オマーンに旅行に行くと言うと大抵周りの人は、「え、オマーンてどこ?」「なんでそんなとこ行くの?」しか言ってこない。 オマーンを選んだのは以下の理由からである。
- 中東の国に行ったことがない
- 中東の中ではUAE、カタールと並んで治安の良い国
- ドバイと比べて外国人労働者が少なくてよりアラブ文化を知れそう
- 人生初の砂漠に行ってみたい
- そのうち人口世界一の宗教になるイスラムの文化を感じたい
旅行の記録
計5日間の旅行だが、フライトが片道15時間ぐらいかかるので現地にいられる時間は2.5日しかない。 旅をしながら考えたこと気づいたことはたくさんあったが、うまくまとめられないので巡った順に書いていく。
1日目
早朝3時にマスカット国際空港に到着し、8時から砂漠へのグループツアーに参加した。本当は移動の疲れが取れた2日目にツアーに行きたかったのだが、その日はツアーをやっていなかったので仕方なく1日目。移動で疲れているところに砂漠のワイルドな運転が襲いかかると車酔いするかと思って一応酔い止めを飲んでおいたが、なくても全然大丈夫だった。悪路という悪路はほとんどなく、道中はかなり綺麗に整備されている高速道路だった。

ちなみに高速道路は国が管理していて国内の高速道路は全て無料である。ほぼ片道2,3車線あって、市街に近いところは4車線もあり、最近も車線拡張工事があったばかりらしい。 所得税もないというので国はどうやって歳入を得ているのかとガイドに聞いたらオイルだそう。これがオイルマネーか。
荒野の中にたまに緑が見える。オアシスのように水が溜まるところであり、パームが植えてある。田舎の人たちはほとんどパーム油の生産をしている農家らしい。

砂漠に入る前に "Air" と看板に書かれた店の前に車が止まる。どうやら砂漠を走るにはタイヤを減圧する必要があるらしい。タイヤに空気が入りすぎているとすぐにスタックしてしまって動かなくなるらしいが初めて知った。砂とタイヤの設置面を増やすのが大事なんだろう、たぶん。(ChatGPTに聞いたらあってた)
砂漠は暑かったが、思ったよりも耐えられる暑さだった。まだ本格的な夏のシーズンでないので市街地で31℃ぐらいで、砂漠は日本の一番暑い夏の日ぐらいという感覚だった。 僕は海辺の町で育ったのだけど、地元の砂丘と比べると砂漠の粒子はその1/3から1/4ぐらいの細かさに感じる。海の砂はザラザラというイメージだが、砂漠はサラサラ。手の甲のシワの隙間にさえ入ってくる。 靴を履いて行ったのだけど、当然のように靴の中には入ってくるし、靴下も砂だらけ。ホテルに帰って靴下を洗ってもいつまでも砂が出てくるので諦めて捨ててしまった。

2週間前の洪水の影響もあり、砂漠は水分を含んでいて、10cmぐらい掘ると湿った砂が出てくる。ぎゅっと握ると手の形に軽く固まるぐらいに湿っている。 砂漠に生息している植物はこの地中の水を吸って生きているらしい。


その後は砂漠の遊牧民ベドウィンの家にお邪魔した。そこは観光客向けに定住している家で、伝統的な装飾品を売っている。そこでオマーンコーヒー、Dates(ディッツ)を貰って、右手だけでどうやってタネを出して食べるかワザを教えてもらった。簡単にいうと人差し指と中指の間にディッツを挟んで親指でタネをその隙間に押し出すのである。日本人としては梅干しのように全部口に入れてから種を出せば良いと思うが、ガイドはありのままの状態でタネを自然に返すために食べる前に出すんだと言っていた。

1300円でベドウィンが飼っているラクダに乗れるとのことなので乗ってみる。歩くリズムは馬よりもゆっくりとのっそのっそと歩き、砂漠のゆったりとした時間の流れを感じられる。なぜかラクダの背中で、これに乗りながら日本でコンビニに行ったら優雅だなとか考えていた。グループツアーに一緒に参加していたインドネシア人と2人でラクダに乗っていたのだけど、もう片方のラクダが自分の足に顔をすりすりしてきた。ラクダに好かれたらしい。
ラクダは座る時に前脚の関節がガクっと急に折れる。乗っている人からすると前に放り投げられそうになるのでラクダに乗る機会があれば降りる時は気をつけて欲しい。

その後はWadi Bani Khalidというオアシスに行った。 知っている人は少ないかもしれないが、オマーンやドバイ周辺で2週間ほど前に1年分の雨が1日で降る大洪水があった [CNNのニュース記事]。2週間前の大洪水で水が増水しているかと思ったら逆で、山から土砂が大量に落ちてきた影響で水溜まりが埋まってしまい泳げる範囲は狭くなっていた。 それでも水が全く無い世界にいきなり大きな水たまりが現れるのは神々しい。

大洪水では17人も死者が出たとの事だったので、ここまでの大洪水は人生で初めて?とガイドに聞いたら2,3年に1度はあることらしい。日本でいう超大型台風的な位置付けの模様。 オアシスに行く道中は土砂崩れで道路が片道通れなくなっていたり、地盤が緩んで陥没していたりそこら中で修繕工事がされていた。 細かなところではあるが、こういった工事にすぐに着手できるのも政府が潤沢なお金を持っている証拠だよなと思う。
砂漠までは片道3時間のドライブなので、帰り道は皆疲れて静かな車内だった。 今回のグループツアーの参加者は自分含めて4人で、1人は石油関係の仕事で出張にきたインドネシア人男性、後2人はアンゴラ出身でドイツで働いている女性2人。年齢は聞かなかったけどおそらく皆30歳手前ぐらいだと思う。なぜかアンゴラ勢は朝から疲れていて行きも帰りもずっと車の中で寝ていたため、道中はドライバーと僕とインドネシア人でオマーンについていろいろ話していた。 そこで得た情報は後半にまとめる。

2日目、3日目
マスカットは観光する場所があまりなくて、残りの2日でマトラスーク(地元の商店街という感じ)とマトラフォート(昔の要塞)、グランドモスク(少し前まで世界最大だったカーペットとシャンデリアがあるモスク)、国立博物館に行った。

特筆することはあまりないけれども、この辺りに行くとオマーンの文化、歴史が分かるのでマスカットに来たなら寄っておくと良いと思う。 どこも観光客で溢れているということはなくて、適度な人数の観光客がいる感じで良い。スークでは「こんにちは」と店主に声をかけれるので中国人との見分けが付くようになるぐらいには日本人は来ているらしい。声はかけてくるがしつこくないし、諸外国でよくあるゴミゴミした場所でのスリも発生しそうな気配はなかったので、治安の良さを感じた。

現地飯にも挑戦してみた。正しくはオマーン料理ではなくてインド料理なのだが、問題はどう頑張って右手だけで食べるかなのでどこの料理でも良いことにする。
店の中に手洗い場があって、店に入るとまずはそこで手を洗う。少し見づらいが下の写真の左端が手洗い場への入口だ。

ローカル過ぎて英語が通じなかった。メニューくれとジェスチャーでお願いするがメニューなんかない口で言え!のようなことをアラビア語で言ってくる。CurryとChickenは通じたような気がしたがまだなんか言ってきてどうしようもないので近くで食べていた人のものを指差して、これをくれとお願いした。

頑張って右手だけで食べようとチャレンジしたが、チャパティでもない薄く小麦粉を焼いたようなものは右手だけでちぎるのが難しく左手を添えてしまって失敗。食べ終わるとまた手洗い場に行き右手を洗って会計をする。

余った時間はホテルのプールで泳いだり、プールサイドで日に当たりながらYouTubeを見たりしていた。せっかくの休暇なので。

Q&A
旅行中にツアーガイドやタクシードライバーに教えてもらったことたち。
Q.なぜ建物は全て白くて高い近代的な建物がないの?
A.政府が景観保護のために規制をしている。多くの地方政府も同じ政策を取っているようだが、砂漠に向かう道中にはときどきピンクや水色の建物があったりした。

Q.なぜ女性は黒い服を着ているの?
A.実は黒でないといけないという決まりはない。10-20年前まではカラフルな衣装を着ていたが、ファッションの移り変わりで今は黒がオシャレ。黒の下はカラフルな服を着ているとのこと。ガイドは今の黒トレンドがあまり好みではないらしい。
Q.トヨタ、日産、三菱の車をよく見るけど、日本車はなんで人気なの?
A.日本車はBMVやベンツなど欧州の車と比べて熱に強くて長持ちする。ただオマーンは左ハンドルで、法律で右ハンドルの車を運転するのは禁止されているとのこと。少し前はドバイで輸入した日本の中古車を改造して左ハンドルにしてからオマーンに輸入していたらしいが、改造は危険だということでそのルートが禁止され、今は左ハンドル向けに生産された日本車を買うしかないらしい。確かに日本では見ないセダン型のヤリスが走っていた。

Q.街乗りタクシーの運転手も含めて英語を喋れる人が多いけど、なんで?
A.まずそんなに英語は喋れるとは思ってないよ(笑) とのことだったが、少なくとも日本人よりはペラペラ喋るので深堀りすると、英語教育では読み書きよりも聞く話すを重視しているとのこと。日本人は読み書きはできるけど喋れないと説明したら、オマーン人は英語は書けないけど喋れると言われた。なるほど。また、ヨーロッパの企業が進出して来ているので、そこで働く人たちは英語を使うとのこと。タクシーの中で流れていたラジオも英語のチャンネルがあったので英語に触れる機会は確かに多そう。
学問をやるとなると英語の読み書きはやはり重要になるが、日本も観光業を押していくのであれば、進学率のそこまで高くない高校では会話に重点をおいた英語の授業をするとか良いのでは?と思う。そうすることで地方でも外国人が観光しやすくなりそうな。
後はやはりタクシーの運転手が英語を喋れるだけで移動中に現地のことが聞けてQuality of Travelがかなり上がるので、日本でもタクシー料金を2倍ぐらいにして若者にタクシードライバーになって欲しい。(日本なんて公共交通機関発達してるんだからタクシーもっと高くて良いでしょ)

Q.14時で道路混んでるけどどういうこと?仕事中じゃないの?
A.政府関連の仕事は14時に終わり、一般企業は16-18時ぐらいに終わるので8-9, 14-15, 16-19時がラッシュアワーになる。と言っても車線が十分に広くて車の台数も多くないので、渋滞と言ってもほとんど車が止まることはない。ちなみにマスカットの人口は100万人で人口密度は東京の1/75。
道路も立体交差やラウンドアバウトが多く、信号が不要な作りになっている。首都のマスカットでさえ移動中に見た信号は4,5個だけ。ラウンドアバウトは車両数が少ない時には快適だけど、ラッシュアワーになって渋滞すると途端に効率が悪くなって信号の方が良さそうだと学んだ。信号がないとスピードを出しすぎてしまうのか、スピードバンプも多い。

マスカット旅行Tips
これからマスカットに旅行に行く人へのアドバイス。(いるのか?)
- 旅行時期は夏を避けるべき。5-10月あたりの本格的な夏は湿気の多い暑さで観光どころではないので、冬に行くのが良さそう。GWはギリギリ夏の始まりとのことなので、まだ耐えられる。オマーンの学校は3ヶ月の夏休みがあるらしいのでそこからも夏の暑さ具合が伺える。
- カーディガンを1枚持っていくと便利。観光客に対しては女性も含めて、肌の露出に関しては干渉してこず、好きな服を着れば良いよというスタンス。僕も一応モスクにカーディガンを羽織って行ったのだが、入り口でスタッフに「それ暑いでしょ脱いで良いよ」と笑われた。カーディガンが便利なのは室内での温度調整が楽にできること。エアコンが強めに効いているところもあり、半袖では寒い。現地がいくら暑かろうとも飛行機の中は行先に関わらず少し寒いので、薄手のパーカーか何かはそもそも持っていくことになるのだけれども…。
- 現金は10 OR(4200円)ぐらい常に持っておいた方がよい。多くの店でクレジットカードのタッチ決済ができる端末が導入されているが、時々決済端末が壊れていてカード決済できなかったり、現金のみの店があるので10 ORぐらい手元にあると安心。観光地の窓口でさえも端末が壊れてたことが2回もあり、現金に救われた。街中のATMもよく壊れていて引き出せないことがあるので、現金ない→近くのATM壊れてる のダブルコンボにやられないように気をつけたい。オマーンの通貨には硬貨もあるが、ほとんど使われておらず最小紙幣の0.1OR (40円)が実質最小単位なので、財布はマネークリップでも十分。
- 物価は日本とほとんど同じか少し安いぐらい。食べた食事の中で一番安いのは0.4OR(167円)の朝ごはんカレー。一番高いのはホテルすぐ近くのショッピングモールにあるスモークチキンプレートで10OR。現地の人の一食の平均は1.5-2.0OR(600-800円)ぐらいだそう。ホテルは1万円弱で4星ホテルに泊まれるが、そのレベルでも歯ブラシやガウンはなかったので、自分で持っていこう。
- 移動はOTAXIのアプリが大変便利。OTAXIが唯一のスマホからタクシーを呼べるタクシーで、かつ唯一のメータータクシー。公共交通機関が全くと言って良いほどないので、ほぼタクシーで移動することになる。一応Googleマップで移動経路を検索するとバスが出て来るが、街中でバスが走っているのはほぼ見ない。ネットや本でルートタクシーについての記述もあるが、2024年現在現地民もほとんど使っている様子がないのでOTAXIでの移動が無難。だいたい1分乗って100円ぐらいの感覚で初乗りが400円。タクシーに乗らなくてもアプリでルートを指定した瞬間に値段が分かるので超便利。ホテルや政府関係の建物には高級タクシーしか乗り入れできないという規制があるようで、OTAXIでホテルまで呼んでも近くの道路まで出てきてと呼び出される点は注意。そのために電話がかかってくるので現地で通話可能なSIMカード(eSIMが便利)の契約をオススメする。

まとめ
細かくいろいろと書いたが総括すると治安は良く平和で、オマーン人は人柄も良かった。再度訪れたいかと言われると、見るものは一通り見たのでもうしばらくは行かなくても良いかなという感じ。20年後ぐらいに変化を見にまた行きたい。一番最初に書いたオマーンに行きたい理由ははまさにそのままだったので、それに魅力を感じた人は是非訪れてみると良いと思う。 急ぎ足で良い人はマスカットは2日あれば十分で、1日は砂漠ツアー、1日は市内散策で問題ない。日本から行くと大抵アブダビ経由になるので時間に余裕があればドバイなどUAEの国にも寄って比較すると面白そう。
以上、山と海に囲まれたオマーンの熱海(?)マスカットでした。

転職
2023年8月1日に株式会社DEGICAに転職した。ポジションは引き続きSRE。前職のoViceには2021年11月入社なので、1年9ヶ月在籍していたことになる。 その前のLAPRASでは5年在籍中4年間(少し手を動かしつつも)マネージャー的な動きをしていて、oViceでもSREチームでリーダーをしていたので、一旦マネジメントよりもIC(Individual Contributor)としてしばらく技術の研鑽に集中したいなという思いで転職した。
幸か不幸か、チームリーダーやCTOとして数年働いた経験はあるにも関わらず、いちエンジニアとしてチーム専属のマネージャーのもとで働いた経験がほとんどなく、自分に時間をかけてくれるマネージャーがいる元で働くのはどういう体験なのかというのを知りたかった。5年後ぐらいにはまたマネージャー/リーダーとして働きたいと思っているため、自分がICを経験することでどういったサポートをされるとICは動きやすいのかを身をもって体験できる機会が欲しかったのである。
(エンジニアはICとマネージャーでキャリアパスが別れていることが多いがそれでも) リーダーからICにポジションを変更しつつ年収を維持する転職活動は比較的大変だった。今回は急いで転職ということはなく、2023年初頭からゆるゆると転職活動をしていたのだが、USの金利上昇による市況の悪化から外資系企業の日本/APACポジションはバタバタと閉鎖され、(自分は観測できなかったが)日本でも採用を縮小している企業が多いと聞いた。そんな中DEGICAはここ数年業績も調子が良く、文化を聞いても長く働けそうということでDEGICAで次の挑戦をすることにした。
DEGICAは日本の企業でありながら、創業者がカナダ出身であることも影響して、エンジニアは9割が外国人で日本人がほとんどいない。しかもフルリモート可にも関わらず、ほぼ全員が日本に移住してきているので、同じタイムゾーンで日中いつでも英語を喋ることができる環境になっている。oViceでも英語を使用していたが、エンジニアは主に日本とチュニジア(-8時間)にいたので、日本時間は日本語で話していて、終業間際のチュニジア側との同期のときだけ英語を使っていた。それと比べるとDEGICAは常に英語学習ができて最高の環境である。英語を伸ばしたいのは、30代のうちに所謂BigTechレベルの企業の日本/APAC支社のポジションで働いてみたいなという思いがあるのと、日本経済の将来が不安過ぎるので将来外資系企業が大量に侵入してきても60歳ぐらいまではそこそこの収入で働ける準備をしておきたいという2つの理由がある。機械翻訳の英語では満足しない理由は2年前に記事を書いていて、その考えは今も変わっていない。
DEGICAにはどれぐらいいるかまだわからないけれども、少なくとも3-5年ぐらいは関わりたいなと思っており、その間に以下のことは達成したい。(上から優先順位高)
- ネイティブ英語話者と対等に会話ができる
- 決済プラットフォーム(PSP)のセキュリティ標準である PCI DSS に準拠したインフラを運用することで、セキュリティの知識を高める
- クレジットカード決済周りのドメイン知識を身に付け、エキスパートと言えるレベルになる
- フラッシュセール等によって発生する予測できない突然のスパイクリクエストにもサーバーが耐えられる (且つコスト効率が良い) 最高のアーキテクチャを考える
30代は一番仕事に脂が乗っている時期であるが、一方で子育てにも時間を使いたいので、できるだけ長期間1つの会社に所属することで余分なオーバーヘッドは減らして、腰を据えて重要な課題に取り組んで行きたい。 40代以降は職種、役職にあまり囚われず、自分が解決したい社会課題に挑戦している企業で貢献したいと思っているが、果たして10年後は何を考えているだろうか。
中古マンションを買ってリフォームした話
最後の記事から2年近く経つが面白いトピックがなかったので仕方ない。 不動産の価格がここ数年間年率5-10%ぐらいで高騰していて、不動産バブルなんじゃないかと疑心暗鬼になっている中、都内に中古マンションを買ってしまったのでそれについて書く。
- なぜこのタイミングで買ったのか
- 購入に際し何を検討したか
- なぜ自分でリフォームしたか
について書こうと思う。 リフォームについては別途記事が書けそうなので、書け次第ここからリンクを貼る。
まず、なぜこのタイミングで買ったのかについて。答えから言えば、広い家が必要になったから。住む家は相場ではなく必要になったタイミングで買えという話をよく(?)聞くが、まさにそれ。昨年こどもが生まれて、最近はうろうろと動き回るようになり、こどもの荷物も増えてきた。その上、夫婦で家でリモートワークをしているので現在の2LDKの賃貸ではさすがに狭い。ということで、現住所から徒歩3分のところにある3LDKの築20年のマンションを買った。 不動産バブル疑惑に関しては、多少その可能性はあると感じつつも、
- バブルが弾けてゼロ金利政策前の2012年水準に戻る30-40%前後の価格暴落が起きてもローンの支払い金額が変わるわけではないので影響は少ない。(売るにしても次に買う場所も安いので気にしない)
- 住宅ローン金利の上昇により支払金額が増えても、現在のリタイア計画である63歳から2-3年延長して働き続ければ今の資金計画は破綻しない
という観点から十分にリスクを取れる状況にあると判断した。
が、基本的には今の値上がりはバブルではなく、都心への人口集中と、デフレ&円安の結果による海外投資家からの買い圧力によるものであるという考えを持っている。最近ちきりんのVoicyを聞き始めて、バックナンバーに都内の不動産の話があったので課金して聞いてみたが似たようなことを言っていた。(link) 人口減少によって遠い将来不動産価値が下がるので賃貸の方が良いのでは論に対するカウンターとしては、住んでいる区が2050年を超えると人口が減ると予想を出しているが、アクセスの良い(そこそこ主要である路線の駅から徒歩3分)マンションを買うことで人口減少の影響をできるだけ受けにくくしたつもりである。
次に購入にあたって何を検討したか。いろいろ検討しすぎて整理して書くのが難しいが頑張って書く。
1. 都内に住むべきか近隣の県に逃げるべきか
自分が見ていた条件だと都外に逃げることで20%ぐらい価格が抑えられた。しかし以下の課題が発生する。
- 今は夫婦ともリモートワークなので良いが、出勤することになったら通勤時間がもったいない。
- 将来的な人口減少により不動産価値が下がる可能性がある。(自分達には影響が少ないが相続した子や孫が得られる価値が下がる)
- 子が中学受験をしたいとなったときに通学に時間がかかる or 通える学校の選択肢が減る
- 引っ越し先で保育園に入れられる確証がない
その他いくつかあるが書かないほうが良いこともあるので、省略する。このデメリットを20%分の差額で受け入れるか、金で解決するかという判断をしたが金で解決することにした。
2. 3LDKの賃貸ではダメなのか
これから5年、10年、15年賃貸に住んで、その後に家を購入するパターンでかかるお金の合計を計算したが、購入の方が安いという結論になった。(固定資産税とか引っ越し費用とか、水回りの修繕とか全部込み。) もちろんグレードの低い物件に賃貸で住めば賃貸の方が安くなるのだが、家を買うケースと同じグレードの物件に賃貸で住むことを考えると購入したほうが安い。後は賃貸のメリットとして家に飽きたら引っ越して気分転換ができる、キッチン/お風呂等の家具が古くなってきたらそれらがキレイな物件に引っ越すことで実質タダ(?)で家具の更新ができるというものがあるが、こどもができてしまうと(校区を離れて)引っ越すのは心理的コストが大きく、それがメリットとして機能しづらくなる問題もある。 あと探していた地域では良さげな賃貸はなぜか定期借家3-5年ばかりで、その頻度で引っ越すのはさすがに辛すぎた。(貸す側の心理はわかる)
3. 築何年の物件を買うべきか
新築は高すぎて手が出なかった。新築は今まで誰も住んでいないことにプレミアがついていて、住んだ1日目に一気に価値が下がるのでそもそも買いたいとはあまり思わない。続いて古い方から見ていくと1983年以前の物件は旧耐震の可能性があるので、これを許容するかどうかという話が出てくる。やはり旧耐震の物件は売れ残りがちに見えたが、旧耐震だから一気に値段が下がるということは無いように感じた。特段安くなるわけではないのであれば、あえて旧耐震を選ぶ必要もないので基本的には新耐震で見ていた。 妻が他人が使った水回りの設備をそのまま使いたくないという性格なので、リフォームなしでも住めるような築15年以下ぐらいの物件はコスパが悪かった。必然的に15-40年弱ぐらいの枠で探すことになる。
問題は買った後に何年住めるのか、いつ建て替えるのかである。現存のマンションがあと何年持つのかは(たぶん)誰にもわからないし、購入時点で参考にできるのは定期的に大規模修繕がされているかどうかぐらいである。あとはコンクリートの強度で(本当かどうか分からないが)100年コンクリートといった謳い文句のコンクリートを使っているマンションもあり、管理組合に聞けばそれかどうか分かるかもしれない。基本的には修繕費が十分に溜まっており、大規模修繕が必要なときに行われているかどうかを見るしかない。マンションを複数見て知ったが、少なくないマンションで修繕費が不足していて or 想定以上に大規模修繕にコストがかかっていて、多くの管理組合では銀行から借り入れを行っている。
建て替えについては、住民の8割の賛成が必要なのでそもそも建て替えが現実的ではない論が主流だが、建て替え時に今よりも面積が広いマンションを建てられるのかは確認しておく価値がある。現物件の容積率は物件の資料に載っているだろうし、その土地の容積率は行政が公開している。容積率に余裕があればマンションの建て替え時に部屋数を増やせるので、その販売利益を立替費用に充てられて現住民は低コストで建て替えができる。こうなれば建て替え反対住民を多少説得しやすくはなるだろう。一方でマンション建設後に行政が容積率を減らした等の理由で、容積率を既にオーバーしている物件もある。これは上と逆のことが起きるので建て替えは厳しい道となる。20年30年後に売る計画であったとしても、築年数が増す毎にこの観点での評価の重みが増すように感じるので、見ておいて損はないと思う。
話は戻って、なぜ築20年の物件を買ったかというと、たまたまこの物件が長期間売れ残っていて交渉により表示価格よりも安く購入できそうだったことと、周辺には築40年前後の物件が多く、築20年物件の競合が少ないため値崩れしづらいだろうということで購入した。(上で話したこと全然気にしてないじゃん。。) 買った後に売主から新築時のパンフレットを貰って知ったが、なんとこの物件は100年コンクリートを使っていた。やったね!
そろそろ最後のトピックに行こう、なぜ自分でリフォームしたか。そもそも築20年の物件ではリフォームされた状態で売られていることは少ない。築30年を超えてくると多くがリフォームされていて、40年ぐらいになるとほぼ確実にリフォームされている。リフォームされて売りに出されている物件のほとんどはリフォーム会社が中古物件を買って自分たちでリフォームして、それを売っている。つまり私達が買う前にすでに一度売買されており、その仲介料も価格に組み込まれている"はず"である。自分が見ていた地域ではリフォーム前後で1000万円強ぐらいの差があったように感じる。全く同じ条件での前後を比較できないので、近い条件の物件を比較することになるのだけど、1-2年ずっと不動産ポータルサイトを見ていたのでそんなにズレた感覚ではないと思う。とある情報筋によるとリフォーム会社は繋がりのある法律事務所から、ローン返済不能になって銀行に引き渡された物件を紹介してもらって市場価格よりも安く物件を仕入れてリフォームして高く売っているらしい。(ずるいじゃん)
特にインテリアのこだわりがなければリフォーム済の物件を買えば良いと思うが、気にしたいのは配管がきちんと交換されているかどうか。築30年を超えていればほぼ確実に交換されているだろうが、築20年でリフォームされているけど給湯管だけリフォームされていない(耐用年数25年の素材です)とかなると、購入後5年で床を剥がして給湯管を交換するハメになる。そういうことが気になってしまう僕のような心配性の人はリフォーム前の物件を買って、リフォーム会社と一緒に家のしくみを勉強しながらリフォームすると良いと思う。 うちのケースでは各部屋の扉と収納以外ほぼすべてリフォームしたが、650-700万円ぐらいだった。リフォーム前物件特有の購入後リフォーム期間約3ヶ月は住めない事による住宅費2重課金問題を考慮しても、リフォーム済の物件を買う場合と比較して200-300万円ぐらいは浮いたと思う。リフォーム済物件の場合は今回リフォームしなかった扉や収納もリフォームされていることが多いので単純には比較できないが、残せるものは残すという選択ができるのも自前リフォームの特権である。一方でリフォームするには大変な労力がかかるので、大量時間が取られる一大プロジェクトとなることは心に留めておいたほうが良い。きっとゼルダをクリアするよりも時間を取られるよ。これについては次回の記事で。
最近英語を勉強している理由の整理
ここ2ヶ月ぐらい英語勉強熱が高まっていて、2週間前にはTOEICを受けてきた。(人生初TOEICだったけど870点取れて嬉しい)
2年前の記事にDMM英会話の勉強ログ があるように、定期的に英語勉強するぞ!という気持ちになるのだけど、半年ぐらいで飽きてしまうのでなぜ英語を勉強しようと思った(思えている)のかをまとめることにした。
忙しい皆さんのために結論から書いておくと
- 英語ができることが強みになるというよりは、英語ができないことで失っている機会が多いように感じている
- これから機械翻訳が発達しても、英語が"話せる"ことは一定の価値がありそう
という2点が自分の中でしっくりくる理由だった。
前者の機会損失の話からすると、給与の高い外資系の会社、グローバルにサービス展開していてインフラエンジニアとして関わると楽しそうな会社で働こうとすると当然英語が必要になる。(念の為、今転職を考えている訳ではない)
突然そういうイイ話が降ってきたときに「あぁ英語ができたらすぐに関われるのに…」となっていては遅いので、いつ来るかわからないその時に備えておきたいという気持ちがある。プログラミング技術に関しては、業界に5,6年いると(めちゃくちゃマニアックなものでなければ)だいたい1ヶ月ぐらい本気出せばなんとか対応できる感覚があるが、自然言語に関しては少なくとも自分はそんなに早く習得できる自信がなくて、ゆっくり長く勉強していく必要があるように感じている。
アラサーなのでそろそろ子供だー家だーを考えないといけなくなって来て、「お金必要だなー」 → 「高給な仕事ってどんなのだろう」 → 「あー英語必要なのねー」 になることが多い。 贅沢しなければそんなにお金いらないけど、根が負けず嫌いなので、ぼーっとしていて周りに抜かれていくのがストレスに感じてしまうのだと思う。
次に、後者の機械翻訳が発達しても、英語が"話せる"ことは一定の価値がありそうに思っている話。
大学時代は、機械翻訳まじで頑張ってくれと祈りながら英語の勉強を放棄していて、機械翻訳が発達すれば英語できることが付加価値にならないと思っていた。
それから5,6年経った今ではDeepLみたいに深層学習で機械翻訳の精度は一気に上がったし、音声認識の精度も上がってきているので、近いうちにオンラインミーティングでリアルタイム翻訳とかできるようになると思う。
そのまま技術が発達していったとして、どこまでスムーズに他言語コミュニケーションが取れるか考えてみる。すると最後にボトルネックになるのは、言語の文法の違いだと思う。
(自然言語処理の専門家ではないので適当なことをいうけど) 例えば英語から日本語にリアルタイムに変換するのに、英語で一文を言い終わっていない状態でリアルタイムに日本語に訳すのは無理に近いんじゃないだろうか。つまり最速でも「相手が話し終わる」 → 「日本語を聞く/見る」 → 「日本語で返事をする」というコミュニケーションになる。
これは顧客との商談などであれば十分なコミュニケーション速度だろうが、毎日一緒に働く同僚とのコミュニケーションがこれではかなりストレスに感じる。
"話せる" を強調したのはこういうことで、読み書きに関しては英語ができることの価値は低くなっていくように思える。
こうなると日本の英語教育は今後どうなるのだろう。大部分の人は機械翻訳で十分なので英語を勉強する人は減るのだろうか。そうなると英語が話せるおじさんはより貴重な存在になるので、こちらとしてはありがたいなと思うのだけども。
と言うと、なんで会話力つかないTOEICなんか2ヶ月間もやっていたのという話になるのだけど、2年前にDMM英会話をやっていて、当時は文法も忘れかけていたし、出てくる語彙も少ないしで成長の限界を感じたので、もう一度きちんと勉強するかという気になったから。 今回勉強して一旦文法とかこれぐらいでいいやと思えたので、また英会話再開しようかなと思っている。
理論だけでは信用できないので、投資シミュレーションをしてみた
前回の記事にも書いたように、先日「株式投資」を読み、今は「敗者のゲーム
」を読んでいて、いずれも長期のインデックス投資を勧める本なのだが、本当に言われている通りに投資して失敗しないのか不安だったのでシミュレーションをしてみた。
心配だったのは、
- リタイアまで30年投資するとして、29年目ぐらいに株価大暴落したら元本割れするのではないか
- 老後の生活費に不安がなくなった の記事に平均利回り6%で運用できれば〜という試算を書いたが、本当にその通りにいく確率はどれぐらいなのか
ということだった。
今回のシミュレーションでは、
- 株価の推移をシミュレーションする
- その推移に対して、いくつかの投資戦略を実行する
- 最終的なリターンを投資戦略毎に比較する
ということをした。
株価の推移をシミュレーションする
今回は1985年1月から2021年1月までの月ごとのS&P 500の値動きを元にシミュレーションすることにした。
株価が暴落や高騰する時には、数ヶ月に渡ってマイナスの成長をし続けるかと思っていたが、毎月の前月比成長率を算出してみると強い相関はなさそうだった。
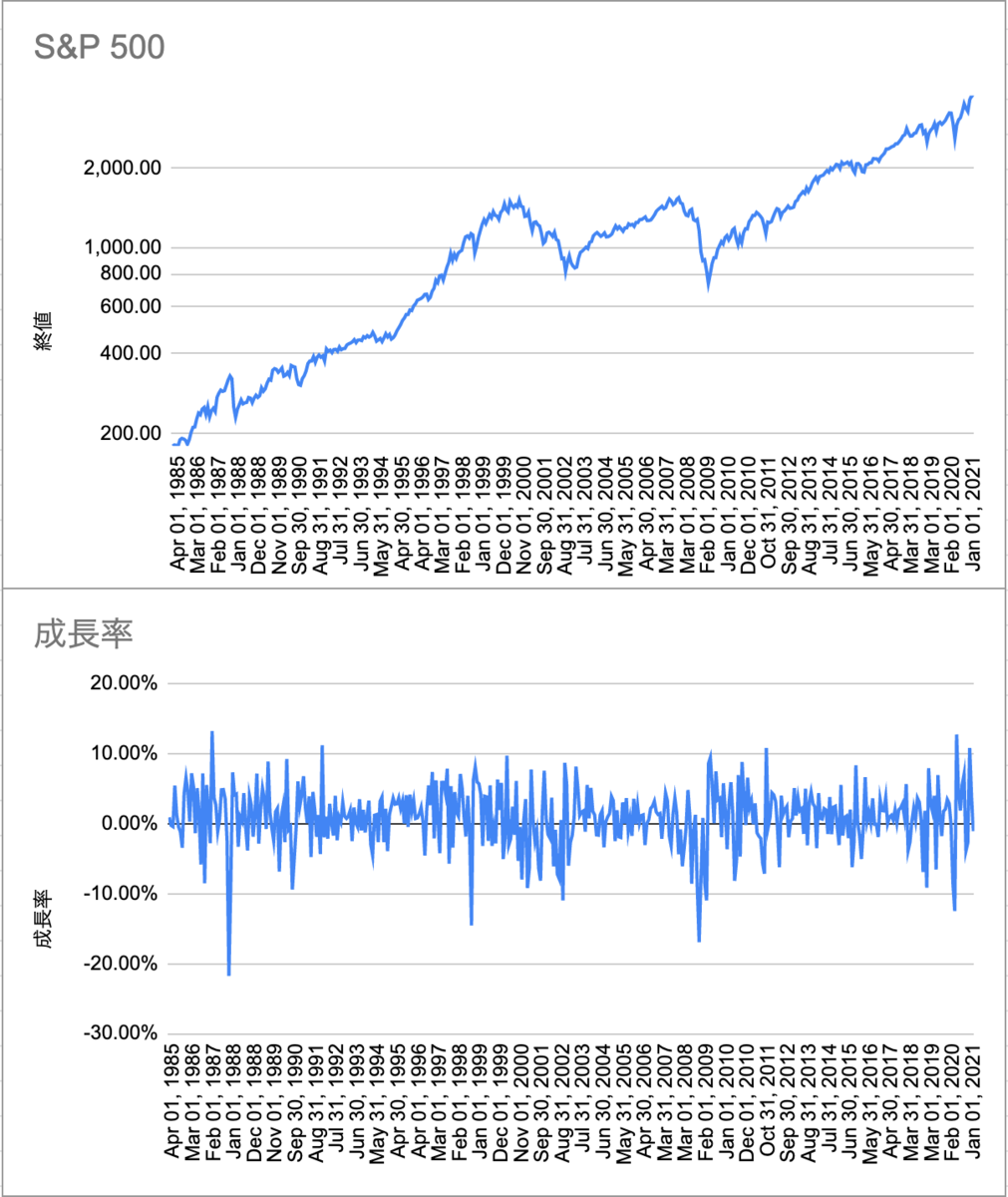
そのため、これらの毎月の成長がランダムな順に起きるとして株価の推移をシミュレーションしてみることにした。

10回試行してみた結果がこちら。
現在の株価を1として、30年分の株価をシミュレートした。
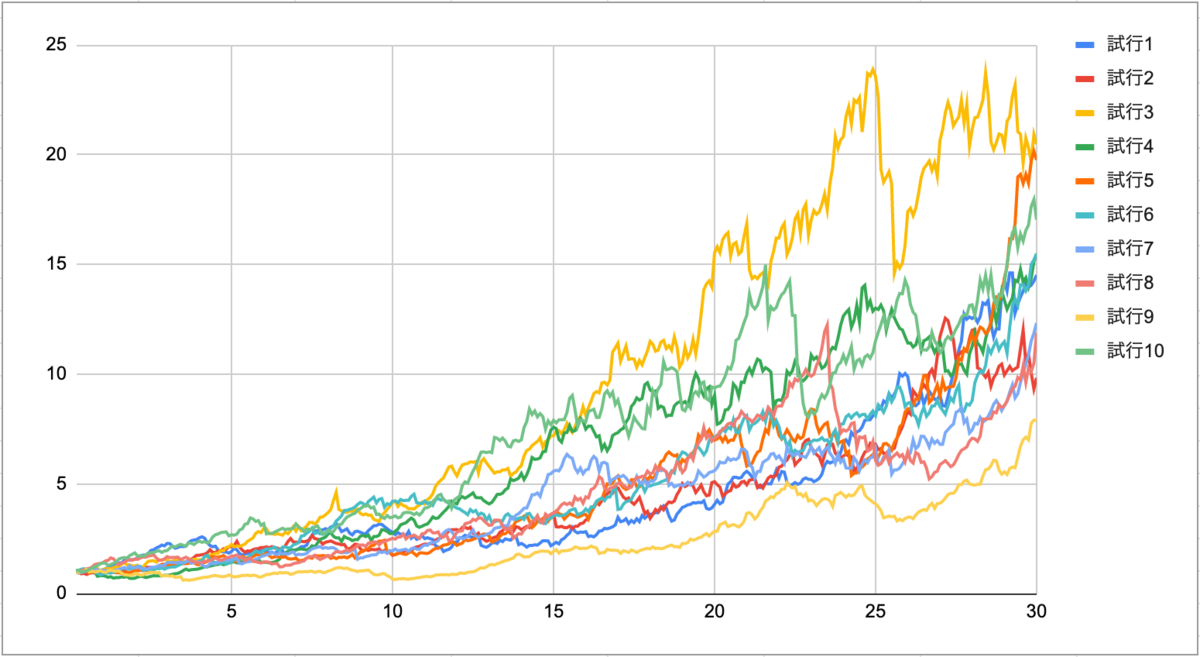
意外とそれっぽい推移になり、最低成長なのは試行9で7.9倍、最高成長なのは試行3で20.5倍となった。2.5倍ぐらいの開きがあるが、逆にそれだけの振れ幅をもってシミュレートできるということである。(大金持ちになるケースも、資産が余り増えないケースも想定できるということ)
色の関係で少し見づらいが、試行8は23年目から暴落が始まり、7年かけて30年目でやっと同水準にもどる例であり、実際に起きたらヒヤヒヤするパターンなんかも含まれていた。すごく単純なロジックで作ったが、割と現実味のあるシミュレーションができた気がする。
その推移に対して、いくつかの投資戦略を実行する
今回は戦略A, B, Cの3パターンを用意した。 いずれも
投資期間は30年 毎月6万円を投資に使える 債券の利回りは、単純化のために国内と海外を半分ずつ持つと想定して、利回り0.5%で固定
という同条件の下で行う。
戦略A
ドルコスト平均法で毎月6万円を固定で株式に投資する ポートフォリオは100%株式
一番単純で、最後まで株式100%のハイリスク戦略。
戦略B
ドルコスト平均法で毎月6万円を固定で株式に投資する ポートフォリオは残年数によって債権と株式の比率を変化させる 比率は「株式投資」の本に書かれていた"リスク容認派"のパターンを参考にして、以下の比率でポートフォリオを組む 残り10年のタイミングで株式88%, 債券12% 残り9年 株式83%, 債券17% 残り8年 株式78%, 債券22% 残り7年 株式73%, 債券27% 残り6年 株式68%, 債券32% 残り5年 株式63%, 債券37% 残り4年 株式60%, 債券40% 残り3年 株式57%, 債券43% 残り2年 株式54%, 債券46% 残り1年 株式50%, 債券50%
長期投資をするならこれが一番スタンダードなパターンだと思う。 (比率は少し違うにしても)
戦略C
戦略Bに加え、以下の条件を加える。 先月からの変化率を x% とした時 * 0% ≦ x: 3万円を投資し、残りの3万円は現金で持っておく * -1% ≦ x < 0%: 6万円をそのまま投資に回す * x < -1%: 6万円に加え、投資せずにそれまでに残しておいた現金も投資に回す
株価が下がった時に多く購入できるように、上がった時には購入量を控える戦略。 戦略Bも入っているため、例えば残り年数1年未満(29年目)のときに変化率が+0.5%だったら、株式投資+1.5万円、債券投資+1.5万円、現金預金+3万円という配分になる。
実は今回のシミュレーションをしようと思ったのは、戦略Bよりも戦略Cの方がより高い確率でハイリターンが得られるのではと思って検証したかったからであった。
最終的なリターンを投資戦略毎に比較する
以上の3つの投資戦略を持って、シミュレーションした株価に対して投資していく。 今回は最終リターンの分布を見たく、多くの試行回数が欲しかったので2000回の株価シミュレーションに対して投資を行った。
その結果がこちら。
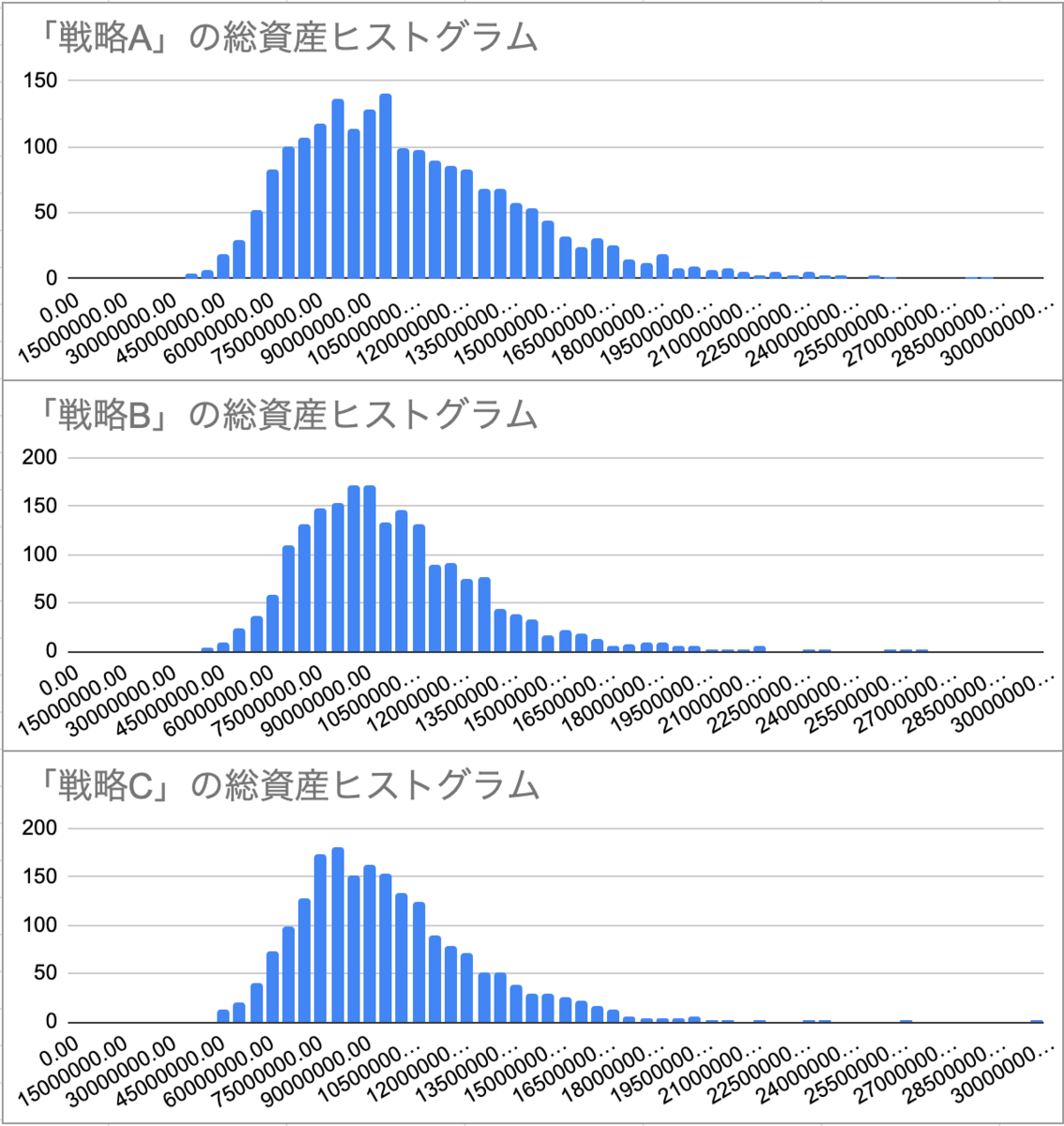
まず最初の感想としては、意外と差がない!ということ。 戦略Aはやはりばらつきが大きく、総資産2億円超えも割とある。が、3000万円台もままある。ちなみに最低額は3280万円だったが、これでも元本の2160万円は割っていない。(ただ、1990~2020年の30年間で物価指数が2倍になっているので、4320万円(元本の2倍)以下はマイナスと考えることもできる)
戦略Bと戦略Cはあまり変わりなさそう。
ヒストグラムだと詳細はわかりにくいので、中央値や標準偏差も見てみる。
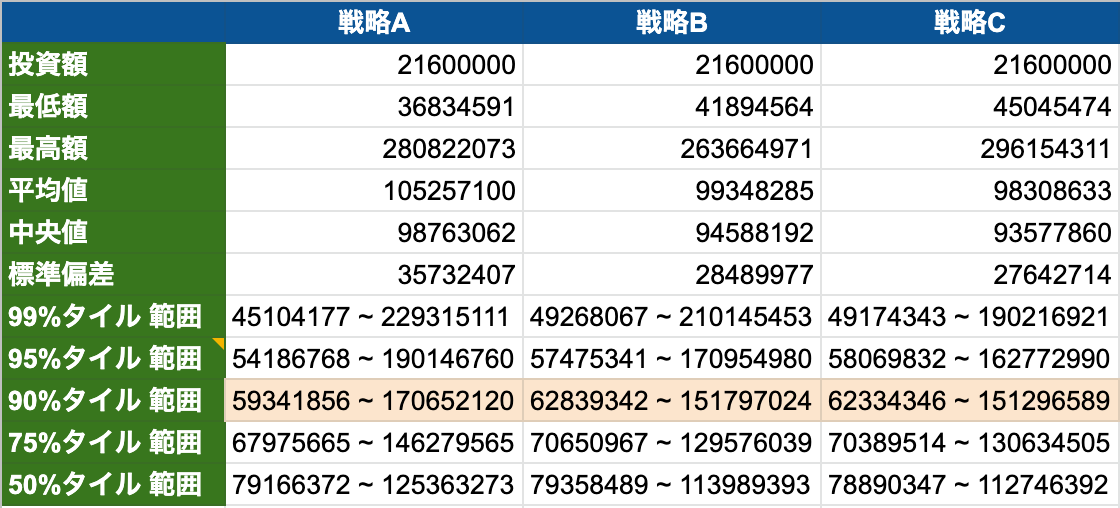
"90%タイル 範囲"というのは、少ない方と大きい方からそれぞれ5%ずつデータを除いた時の最小値と最大値を表している。
どこで比較するかにも依るが、全体的にみると戦略Cよりも戦略Bの方が優れているように見える。 単純に運用コストを考えると、毎月何も考えずに自動引き落としで投資できたほうが楽なので、そこまで考慮に入れるとBの方が勝ちという感じか。
戦略Aか戦略Bかは個人の嗜好によりそうだが、「リタイア時点で少なくとも6000万円は確保しておきたい」というような目標があるのであればAよりはBの方が向いていそうである。
Future Work
今回はS&P 500の過去の値動きから株価をシミュレートしたが、一国の株式市場のインデックスでは情報としては偏りがありそうなので、VTやMSCI ACWIなどの全世界株式インデックスの過去データを用いてやってみたい。(今回情報を持ってきたYahoo! Financeにはそれら2つの値動きが2008年以降のデータしかなかったので、今回はS&P 500を持ってきた)
まとめ
現金が必要になるN年前にはポートフォリオをきちんと考えたほうが良いという話をよく聞くが、思ったよりも100%株式投資でも大丈夫なのではという気分になった。(債券の利回りを少し低めに設定したことが戦略Aを魅力的に見せている可能性がある)
何も考えずにひたすら毎月投資していけば良いこともわかったが、色々考えるのが好きな自分にはインデックス投資向いていないかもという気分にもなってきて難しい。
いずれにしても、こういうシミュレーションをしたいと思った時にさっとコード書いて確かめられるのでコード書ける人間で良かったと思った。 ビジネスマンはスプレッドシートのみでこういうことをやってしまいそうではあるが。