転職
2023年8月1日に株式会社DEGICAに転職した。ポジションは引き続きSRE。前職のoViceには2021年11月入社なので、1年9ヶ月在籍していたことになる。 その前のLAPRASでは5年在籍中4年間(少し手を動かしつつも)マネージャー的な動きをしていて、oViceでもSREチームでリーダーをしていたので、一旦マネジメントよりもIC(Individual Contributor)としてしばらく技術の研鑽に集中したいなという思いで転職した。
幸か不幸か、チームリーダーやCTOとして数年働いた経験はあるにも関わらず、いちエンジニアとしてチーム専属のマネージャーのもとで働いた経験がほとんどなく、自分に時間をかけてくれるマネージャーがいる元で働くのはどういう体験なのかというのを知りたかった。5年後ぐらいにはまたマネージャー/リーダーとして働きたいと思っているため、自分がICを経験することでどういったサポートをされるとICは動きやすいのかを身をもって体験できる機会が欲しかったのである。
(エンジニアはICとマネージャーでキャリアパスが別れていることが多いがそれでも) リーダーからICにポジションを変更しつつ年収を維持する転職活動は比較的大変だった。今回は急いで転職ということはなく、2023年初頭からゆるゆると転職活動をしていたのだが、USの金利上昇による市況の悪化から外資系企業の日本/APACポジションはバタバタと閉鎖され、(自分は観測できなかったが)日本でも採用を縮小している企業が多いと聞いた。そんな中DEGICAはここ数年業績も調子が良く、文化を聞いても長く働けそうということでDEGICAで次の挑戦をすることにした。
DEGICAは日本の企業でありながら、創業者がカナダ出身であることも影響して、エンジニアは9割が外国人で日本人がほとんどいない。しかもフルリモート可にも関わらず、ほぼ全員が日本に移住してきているので、同じタイムゾーンで日中いつでも英語を喋ることができる環境になっている。oViceでも英語を使用していたが、エンジニアは主に日本とチュニジア(-8時間)にいたので、日本時間は日本語で話していて、終業間際のチュニジア側との同期のときだけ英語を使っていた。それと比べるとDEGICAは常に英語学習ができて最高の環境である。英語を伸ばしたいのは、30代のうちに所謂BigTechレベルの企業の日本/APAC支社のポジションで働いてみたいなという思いがあるのと、日本経済の将来が不安過ぎるので将来外資系企業が大量に侵入してきても60歳ぐらいまではそこそこの収入で働ける準備をしておきたいという2つの理由がある。機械翻訳の英語では満足しない理由は2年前に記事を書いていて、その考えは今も変わっていない。
DEGICAにはどれぐらいいるかまだわからないけれども、少なくとも3-5年ぐらいは関わりたいなと思っており、その間に以下のことは達成したい。(上から優先順位高)
- ネイティブ英語話者と対等に会話ができる
- 決済プラットフォーム(PSP)のセキュリティ標準である PCI DSS に準拠したインフラを運用することで、セキュリティの知識を高める
- クレジットカード決済周りのドメイン知識を身に付け、エキスパートと言えるレベルになる
- フラッシュセール等によって発生する予測できない突然のスパイクリクエストにもサーバーが耐えられる (且つコスト効率が良い) 最高のアーキテクチャを考える
30代は一番仕事に脂が乗っている時期であるが、一方で子育てにも時間を使いたいので、できるだけ長期間1つの会社に所属することで余分なオーバーヘッドは減らして、腰を据えて重要な課題に取り組んで行きたい。 40代以降は職種、役職にあまり囚われず、自分が解決したい社会課題に挑戦している企業で貢献したいと思っているが、果たして10年後は何を考えているだろうか。
中古マンションを買ってリフォームした話
最後の記事から2年近く経つが面白いトピックがなかったので仕方ない。 不動産の価格がここ数年間年率5-10%ぐらいで高騰していて、不動産バブルなんじゃないかと疑心暗鬼になっている中、都内に中古マンションを買ってしまったのでそれについて書く。
- なぜこのタイミングで買ったのか
- 購入に際し何を検討したか
- なぜ自分でリフォームしたか
について書こうと思う。 リフォームについては別途記事が書けそうなので、書け次第ここからリンクを貼る。
まず、なぜこのタイミングで買ったのかについて。答えから言えば、広い家が必要になったから。住む家は相場ではなく必要になったタイミングで買えという話をよく(?)聞くが、まさにそれ。昨年こどもが生まれて、最近はうろうろと動き回るようになり、こどもの荷物も増えてきた。その上、夫婦で家でリモートワークをしているので現在の2LDKの賃貸ではさすがに狭い。ということで、現住所から徒歩3分のところにある3LDKの築20年のマンションを買った。 不動産バブル疑惑に関しては、多少その可能性はあると感じつつも、
- バブルが弾けてゼロ金利政策前の2012年水準に戻る30-40%前後の価格暴落が起きてもローンの支払い金額が変わるわけではないので影響は少ない。(売るにしても次に買う場所も安いので気にしない)
- 住宅ローン金利の上昇により支払金額が増えても、現在のリタイア計画である63歳から2-3年延長して働き続ければ今の資金計画は破綻しない
という観点から十分にリスクを取れる状況にあると判断した。
が、基本的には今の値上がりはバブルではなく、都心への人口集中と、デフレ&円安の結果による海外投資家からの買い圧力によるものであるという考えを持っている。最近ちきりんのVoicyを聞き始めて、バックナンバーに都内の不動産の話があったので課金して聞いてみたが似たようなことを言っていた。(link) 人口減少によって遠い将来不動産価値が下がるので賃貸の方が良いのでは論に対するカウンターとしては、住んでいる区が2050年を超えると人口が減ると予想を出しているが、アクセスの良い(そこそこ主要である路線の駅から徒歩3分)マンションを買うことで人口減少の影響をできるだけ受けにくくしたつもりである。
次に購入にあたって何を検討したか。いろいろ検討しすぎて整理して書くのが難しいが頑張って書く。
1. 都内に住むべきか近隣の県に逃げるべきか
自分が見ていた条件だと都外に逃げることで20%ぐらい価格が抑えられた。しかし以下の課題が発生する。
- 今は夫婦ともリモートワークなので良いが、出勤することになったら通勤時間がもったいない。
- 将来的な人口減少により不動産価値が下がる可能性がある。(自分達には影響が少ないが相続した子や孫が得られる価値が下がる)
- 子が中学受験をしたいとなったときに通学に時間がかかる or 通える学校の選択肢が減る
- 引っ越し先で保育園に入れられる確証がない
その他いくつかあるが書かないほうが良いこともあるので、省略する。このデメリットを20%分の差額で受け入れるか、金で解決するかという判断をしたが金で解決することにした。
2. 3LDKの賃貸ではダメなのか
これから5年、10年、15年賃貸に住んで、その後に家を購入するパターンでかかるお金の合計を計算したが、購入の方が安いという結論になった。(固定資産税とか引っ越し費用とか、水回りの修繕とか全部込み。) もちろんグレードの低い物件に賃貸で住めば賃貸の方が安くなるのだが、家を買うケースと同じグレードの物件に賃貸で住むことを考えると購入したほうが安い。後は賃貸のメリットとして家に飽きたら引っ越して気分転換ができる、キッチン/お風呂等の家具が古くなってきたらそれらがキレイな物件に引っ越すことで実質タダ(?)で家具の更新ができるというものがあるが、こどもができてしまうと(校区を離れて)引っ越すのは心理的コストが大きく、それがメリットとして機能しづらくなる問題もある。 あと探していた地域では良さげな賃貸はなぜか定期借家3-5年ばかりで、その頻度で引っ越すのはさすがに辛すぎた。(貸す側の心理はわかる)
3. 築何年の物件を買うべきか
新築は高すぎて手が出なかった。新築は今まで誰も住んでいないことにプレミアがついていて、住んだ1日目に一気に価値が下がるのでそもそも買いたいとはあまり思わない。続いて古い方から見ていくと1983年以前の物件は旧耐震の可能性があるので、これを許容するかどうかという話が出てくる。やはり旧耐震の物件は売れ残りがちに見えたが、旧耐震だから一気に値段が下がるということは無いように感じた。特段安くなるわけではないのであれば、あえて旧耐震を選ぶ必要もないので基本的には新耐震で見ていた。 妻が他人が使った水回りの設備をそのまま使いたくないという性格なので、リフォームなしでも住めるような築15年以下ぐらいの物件はコスパが悪かった。必然的に15-40年弱ぐらいの枠で探すことになる。
問題は買った後に何年住めるのか、いつ建て替えるのかである。現存のマンションがあと何年持つのかは(たぶん)誰にもわからないし、購入時点で参考にできるのは定期的に大規模修繕がされているかどうかぐらいである。あとはコンクリートの強度で(本当かどうか分からないが)100年コンクリートといった謳い文句のコンクリートを使っているマンションもあり、管理組合に聞けばそれかどうか分かるかもしれない。基本的には修繕費が十分に溜まっており、大規模修繕が必要なときに行われているかどうかを見るしかない。マンションを複数見て知ったが、少なくないマンションで修繕費が不足していて or 想定以上に大規模修繕にコストがかかっていて、多くの管理組合では銀行から借り入れを行っている。
建て替えについては、住民の8割の賛成が必要なのでそもそも建て替えが現実的ではない論が主流だが、建て替え時に今よりも面積が広いマンションを建てられるのかは確認しておく価値がある。現物件の容積率は物件の資料に載っているだろうし、その土地の容積率は行政が公開している。容積率に余裕があればマンションの建て替え時に部屋数を増やせるので、その販売利益を立替費用に充てられて現住民は低コストで建て替えができる。こうなれば建て替え反対住民を多少説得しやすくはなるだろう。一方でマンション建設後に行政が容積率を減らした等の理由で、容積率を既にオーバーしている物件もある。これは上と逆のことが起きるので建て替えは厳しい道となる。20年30年後に売る計画であったとしても、築年数が増す毎にこの観点での評価の重みが増すように感じるので、見ておいて損はないと思う。
話は戻って、なぜ築20年の物件を買ったかというと、たまたまこの物件が長期間売れ残っていて交渉により表示価格よりも安く購入できそうだったことと、周辺には築40年前後の物件が多く、築20年物件の競合が少ないため値崩れしづらいだろうということで購入した。(上で話したこと全然気にしてないじゃん。。) 買った後に売主から新築時のパンフレットを貰って知ったが、なんとこの物件は100年コンクリートを使っていた。やったね!
そろそろ最後のトピックに行こう、なぜ自分でリフォームしたか。そもそも築20年の物件ではリフォームされた状態で売られていることは少ない。築30年を超えてくると多くがリフォームされていて、40年ぐらいになるとほぼ確実にリフォームされている。リフォームされて売りに出されている物件のほとんどはリフォーム会社が中古物件を買って自分たちでリフォームして、それを売っている。つまり私達が買う前にすでに一度売買されており、その仲介料も価格に組み込まれている"はず"である。自分が見ていた地域ではリフォーム前後で1000万円強ぐらいの差があったように感じる。全く同じ条件での前後を比較できないので、近い条件の物件を比較することになるのだけど、1-2年ずっと不動産ポータルサイトを見ていたのでそんなにズレた感覚ではないと思う。とある情報筋によるとリフォーム会社は繋がりのある法律事務所から、ローン返済不能になって銀行に引き渡された物件を紹介してもらって市場価格よりも安く物件を仕入れてリフォームして高く売っているらしい。(ずるいじゃん)
特にインテリアのこだわりがなければリフォーム済の物件を買えば良いと思うが、気にしたいのは配管がきちんと交換されているかどうか。築30年を超えていればほぼ確実に交換されているだろうが、築20年でリフォームされているけど給湯管だけリフォームされていない(耐用年数25年の素材です)とかなると、購入後5年で床を剥がして給湯管を交換するハメになる。そういうことが気になってしまう僕のような心配性の人はリフォーム前の物件を買って、リフォーム会社と一緒に家のしくみを勉強しながらリフォームすると良いと思う。 うちのケースでは各部屋の扉と収納以外ほぼすべてリフォームしたが、650-700万円ぐらいだった。リフォーム前物件特有の購入後リフォーム期間約3ヶ月は住めない事による住宅費2重課金問題を考慮しても、リフォーム済の物件を買う場合と比較して200-300万円ぐらいは浮いたと思う。リフォーム済物件の場合は今回リフォームしなかった扉や収納もリフォームされていることが多いので単純には比較できないが、残せるものは残すという選択ができるのも自前リフォームの特権である。一方でリフォームするには大変な労力がかかるので、大量時間が取られる一大プロジェクトとなることは心に留めておいたほうが良い。きっとゼルダをクリアするよりも時間を取られるよ。これについては次回の記事で。
最近英語を勉強している理由の整理
ここ2ヶ月ぐらい英語勉強熱が高まっていて、2週間前にはTOEICを受けてきた。(人生初TOEICだったけど870点取れて嬉しい)
2年前の記事にDMM英会話の勉強ログ があるように、定期的に英語勉強するぞ!という気持ちになるのだけど、半年ぐらいで飽きてしまうのでなぜ英語を勉強しようと思った(思えている)のかをまとめることにした。
忙しい皆さんのために結論から書いておくと
- 英語ができることが強みになるというよりは、英語ができないことで失っている機会が多いように感じている
- これから機械翻訳が発達しても、英語が"話せる"ことは一定の価値がありそう
という2点が自分の中でしっくりくる理由だった。
前者の機会損失の話からすると、給与の高い外資系の会社、グローバルにサービス展開していてインフラエンジニアとして関わると楽しそうな会社で働こうとすると当然英語が必要になる。(念の為、今転職を考えている訳ではない)
突然そういうイイ話が降ってきたときに「あぁ英語ができたらすぐに関われるのに…」となっていては遅いので、いつ来るかわからないその時に備えておきたいという気持ちがある。プログラミング技術に関しては、業界に5,6年いると(めちゃくちゃマニアックなものでなければ)だいたい1ヶ月ぐらい本気出せばなんとか対応できる感覚があるが、自然言語に関しては少なくとも自分はそんなに早く習得できる自信がなくて、ゆっくり長く勉強していく必要があるように感じている。
アラサーなのでそろそろ子供だー家だーを考えないといけなくなって来て、「お金必要だなー」 → 「高給な仕事ってどんなのだろう」 → 「あー英語必要なのねー」 になることが多い。 贅沢しなければそんなにお金いらないけど、根が負けず嫌いなので、ぼーっとしていて周りに抜かれていくのがストレスに感じてしまうのだと思う。
次に、後者の機械翻訳が発達しても、英語が"話せる"ことは一定の価値がありそうに思っている話。
大学時代は、機械翻訳まじで頑張ってくれと祈りながら英語の勉強を放棄していて、機械翻訳が発達すれば英語できることが付加価値にならないと思っていた。
それから5,6年経った今ではDeepLみたいに深層学習で機械翻訳の精度は一気に上がったし、音声認識の精度も上がってきているので、近いうちにオンラインミーティングでリアルタイム翻訳とかできるようになると思う。
そのまま技術が発達していったとして、どこまでスムーズに他言語コミュニケーションが取れるか考えてみる。すると最後にボトルネックになるのは、言語の文法の違いだと思う。
(自然言語処理の専門家ではないので適当なことをいうけど) 例えば英語から日本語にリアルタイムに変換するのに、英語で一文を言い終わっていない状態でリアルタイムに日本語に訳すのは無理に近いんじゃないだろうか。つまり最速でも「相手が話し終わる」 → 「日本語を聞く/見る」 → 「日本語で返事をする」というコミュニケーションになる。
これは顧客との商談などであれば十分なコミュニケーション速度だろうが、毎日一緒に働く同僚とのコミュニケーションがこれではかなりストレスに感じる。
"話せる" を強調したのはこういうことで、読み書きに関しては英語ができることの価値は低くなっていくように思える。
こうなると日本の英語教育は今後どうなるのだろう。大部分の人は機械翻訳で十分なので英語を勉強する人は減るのだろうか。そうなると英語が話せるおじさんはより貴重な存在になるので、こちらとしてはありがたいなと思うのだけども。
と言うと、なんで会話力つかないTOEICなんか2ヶ月間もやっていたのという話になるのだけど、2年前にDMM英会話をやっていて、当時は文法も忘れかけていたし、出てくる語彙も少ないしで成長の限界を感じたので、もう一度きちんと勉強するかという気になったから。 今回勉強して一旦文法とかこれぐらいでいいやと思えたので、また英会話再開しようかなと思っている。
理論だけでは信用できないので、投資シミュレーションをしてみた
前回の記事にも書いたように、先日「株式投資」を読み、今は「敗者のゲーム
」を読んでいて、いずれも長期のインデックス投資を勧める本なのだが、本当に言われている通りに投資して失敗しないのか不安だったのでシミュレーションをしてみた。
心配だったのは、
- リタイアまで30年投資するとして、29年目ぐらいに株価大暴落したら元本割れするのではないか
- 老後の生活費に不安がなくなった の記事に平均利回り6%で運用できれば〜という試算を書いたが、本当にその通りにいく確率はどれぐらいなのか
ということだった。
今回のシミュレーションでは、
- 株価の推移をシミュレーションする
- その推移に対して、いくつかの投資戦略を実行する
- 最終的なリターンを投資戦略毎に比較する
ということをした。
株価の推移をシミュレーションする
今回は1985年1月から2021年1月までの月ごとのS&P 500の値動きを元にシミュレーションすることにした。
株価が暴落や高騰する時には、数ヶ月に渡ってマイナスの成長をし続けるかと思っていたが、毎月の前月比成長率を算出してみると強い相関はなさそうだった。
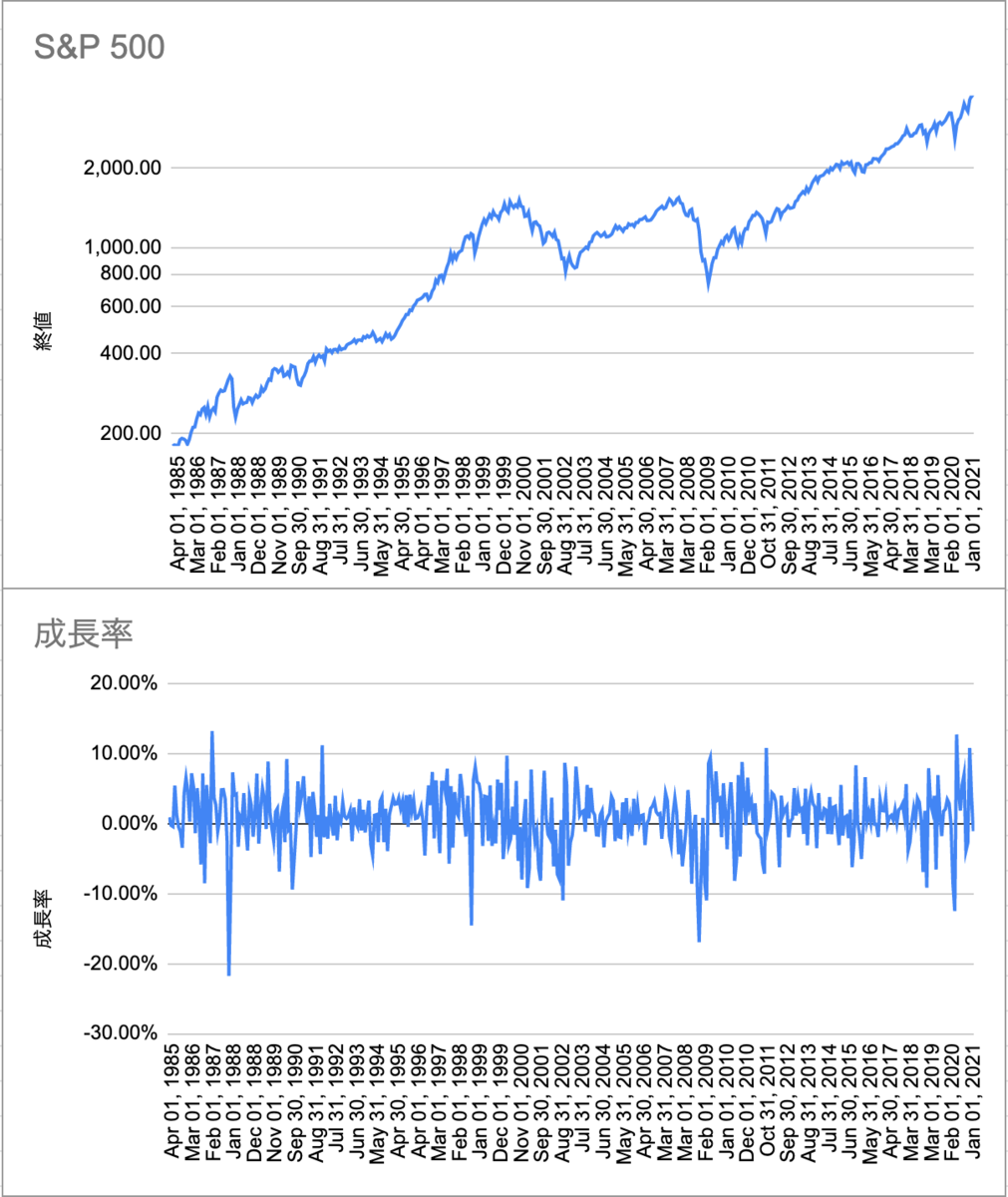
そのため、これらの毎月の成長がランダムな順に起きるとして株価の推移をシミュレーションしてみることにした。

10回試行してみた結果がこちら。
現在の株価を1として、30年分の株価をシミュレートした。
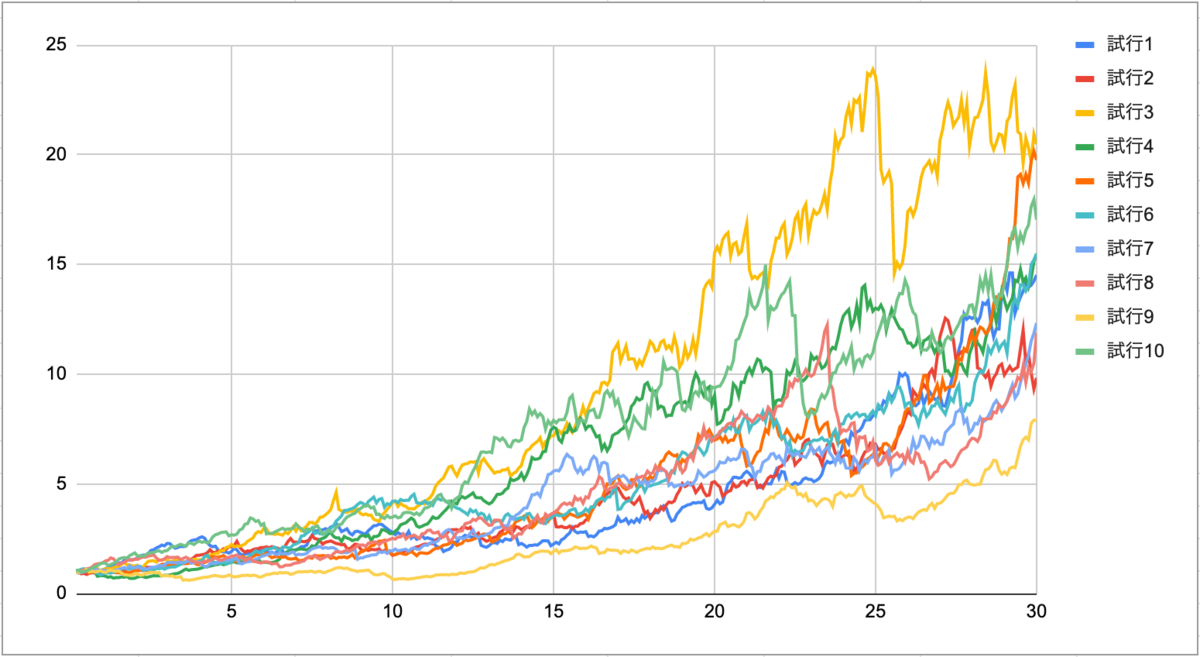
意外とそれっぽい推移になり、最低成長なのは試行9で7.9倍、最高成長なのは試行3で20.5倍となった。2.5倍ぐらいの開きがあるが、逆にそれだけの振れ幅をもってシミュレートできるということである。(大金持ちになるケースも、資産が余り増えないケースも想定できるということ)
色の関係で少し見づらいが、試行8は23年目から暴落が始まり、7年かけて30年目でやっと同水準にもどる例であり、実際に起きたらヒヤヒヤするパターンなんかも含まれていた。すごく単純なロジックで作ったが、割と現実味のあるシミュレーションができた気がする。
その推移に対して、いくつかの投資戦略を実行する
今回は戦略A, B, Cの3パターンを用意した。 いずれも
投資期間は30年 毎月6万円を投資に使える 債券の利回りは、単純化のために国内と海外を半分ずつ持つと想定して、利回り0.5%で固定
という同条件の下で行う。
戦略A
ドルコスト平均法で毎月6万円を固定で株式に投資する ポートフォリオは100%株式
一番単純で、最後まで株式100%のハイリスク戦略。
戦略B
ドルコスト平均法で毎月6万円を固定で株式に投資する ポートフォリオは残年数によって債権と株式の比率を変化させる 比率は「株式投資」の本に書かれていた"リスク容認派"のパターンを参考にして、以下の比率でポートフォリオを組む 残り10年のタイミングで株式88%, 債券12% 残り9年 株式83%, 債券17% 残り8年 株式78%, 債券22% 残り7年 株式73%, 債券27% 残り6年 株式68%, 債券32% 残り5年 株式63%, 債券37% 残り4年 株式60%, 債券40% 残り3年 株式57%, 債券43% 残り2年 株式54%, 債券46% 残り1年 株式50%, 債券50%
長期投資をするならこれが一番スタンダードなパターンだと思う。 (比率は少し違うにしても)
戦略C
戦略Bに加え、以下の条件を加える。 先月からの変化率を x% とした時 * 0% ≦ x: 3万円を投資し、残りの3万円は現金で持っておく * -1% ≦ x < 0%: 6万円をそのまま投資に回す * x < -1%: 6万円に加え、投資せずにそれまでに残しておいた現金も投資に回す
株価が下がった時に多く購入できるように、上がった時には購入量を控える戦略。 戦略Bも入っているため、例えば残り年数1年未満(29年目)のときに変化率が+0.5%だったら、株式投資+1.5万円、債券投資+1.5万円、現金預金+3万円という配分になる。
実は今回のシミュレーションをしようと思ったのは、戦略Bよりも戦略Cの方がより高い確率でハイリターンが得られるのではと思って検証したかったからであった。
最終的なリターンを投資戦略毎に比較する
以上の3つの投資戦略を持って、シミュレーションした株価に対して投資していく。 今回は最終リターンの分布を見たく、多くの試行回数が欲しかったので2000回の株価シミュレーションに対して投資を行った。
その結果がこちら。
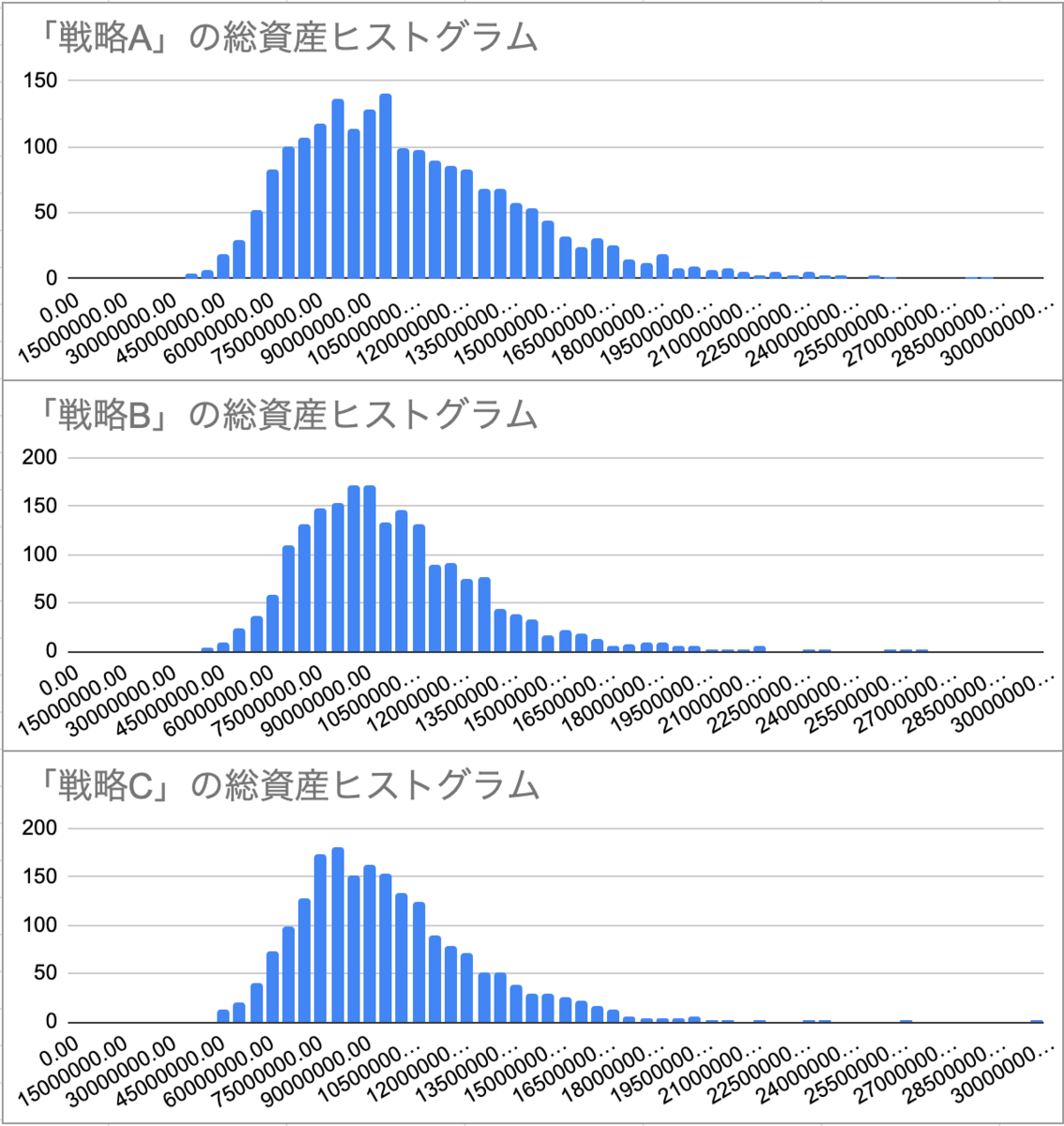
まず最初の感想としては、意外と差がない!ということ。 戦略Aはやはりばらつきが大きく、総資産2億円超えも割とある。が、3000万円台もままある。ちなみに最低額は3280万円だったが、これでも元本の2160万円は割っていない。(ただ、1990~2020年の30年間で物価指数が2倍になっているので、4320万円(元本の2倍)以下はマイナスと考えることもできる)
戦略Bと戦略Cはあまり変わりなさそう。
ヒストグラムだと詳細はわかりにくいので、中央値や標準偏差も見てみる。
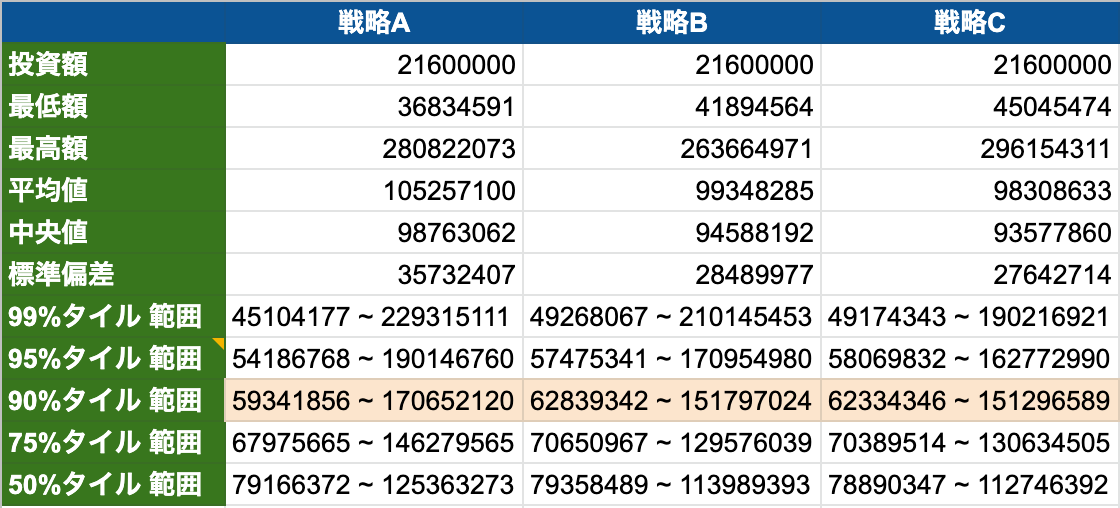
"90%タイル 範囲"というのは、少ない方と大きい方からそれぞれ5%ずつデータを除いた時の最小値と最大値を表している。
どこで比較するかにも依るが、全体的にみると戦略Cよりも戦略Bの方が優れているように見える。 単純に運用コストを考えると、毎月何も考えずに自動引き落としで投資できたほうが楽なので、そこまで考慮に入れるとBの方が勝ちという感じか。
戦略Aか戦略Bかは個人の嗜好によりそうだが、「リタイア時点で少なくとも6000万円は確保しておきたい」というような目標があるのであればAよりはBの方が向いていそうである。
Future Work
今回はS&P 500の過去の値動きから株価をシミュレートしたが、一国の株式市場のインデックスでは情報としては偏りがありそうなので、VTやMSCI ACWIなどの全世界株式インデックスの過去データを用いてやってみたい。(今回情報を持ってきたYahoo! Financeにはそれら2つの値動きが2008年以降のデータしかなかったので、今回はS&P 500を持ってきた)
まとめ
現金が必要になるN年前にはポートフォリオをきちんと考えたほうが良いという話をよく聞くが、思ったよりも100%株式投資でも大丈夫なのではという気分になった。(債券の利回りを少し低めに設定したことが戦略Aを魅力的に見せている可能性がある)
何も考えずにひたすら毎月投資していけば良いこともわかったが、色々考えるのが好きな自分にはインデックス投資向いていないかもという気分にもなってきて難しい。
いずれにしても、こういうシミュレーションをしたいと思った時にさっとコード書いて確かめられるのでコード書ける人間で良かったと思った。 ビジネスマンはスプレッドシートのみでこういうことをやってしまいそうではあるが。
「株式投資 長期投資で成功するための完全ガイド」を読んでインデックス投資は自分との戦いだと思った
昨年末からインデックス投資を初めて、インデックス投資をしている人のブログをいくつか読んでいたのだけど、よくオススメされている本に「株式投資」があったので読んでみた。
平均株価は過去200年の推移を見ると成長し続けているので、長期に渡って株式に投資していれば低リスクで資産は増える。(※) そして、その平均株価に沿って投資するためにはインデックスファンドに投資するのが良いよ。ということを過去のデータを用いて定量的に語っている本だった。 (※ 40年に1回ぐらいガツンと株価が下がることがあるので、老後の生活が近い場合はきちんとポートフォリオを考える必要があるよ)
印象的だったのは
- 世の中の8割のアクティブ運用ファンドはインデックスファンドよりも利回りが低い。それはファンドマネージャーが買う銘柄が悪いわけではなく、年間平均で2%程度かかる手数料と売買コストによるもの。
- IPO株はたまに数十倍もの株価になるものがあるので、それに目がくらんで買ってしまいがちだが、そのすべてを買うよりもラッセル2000小型株指数の方が利回りが高い。
- 頻繁に売買するトレーダーの利回りはあまり売買しないトレーダーよりも7.1%下回っていたという研究がある。
ということ。
個別銘柄の調査に十分な時間が割けないのであれば、インデックスファンドに長期投資しておくべきで、そうすれば過去のデータからインフレ調整済み利回りで6.8%、インフレ率が2,3%のままとすれば名目の利回りは9~10%で資産が増えて行くことがわかっている。 しかし「XX社の株価が1年でN倍に!」みたいなニュースを見たり、隣人がそれで儲けたという話を聞くとそれが魅力的に映り、6~10%の利回りでは物足りない、刺激が足りないとなり、行動が変わってしまい本来インデックス投資していれば得られるはずだった利益よりも低い利回りになってしまうことが多いとのことだった。
「20年30年、毎月5万円ずつインデックスファンドに投資する」と言葉で書けばとても単純だが、そのルールを守って実践し続けるのは難しく、インデックス投資は自分との戦いなんだなと思った。
老後の生活費に不安がなくなった
2020年末はコロナの第三波で実家に帰省できなかったので、自分の時間が意外と多く、中古マンション購入についてや生涯の生活費について調査・計算をしていた。
中古マンションは2LDKリノベ済築30年ぐらいのやつを買って、15年ぐらい住んで子供が中学生ぐらいになり一部屋追加で欲しくなったタイミングで売却するという方針で試算していたのだけど、結論は賃貸で行くことにした。 この話の詳細は気が向いたらまた別で書こうと思う。
(まだ子どもはいないが)妻とは2人子どもが欲しいよねーと話をしていて、大学は国立でお願いするとして、大学院まで行くと1人育てるのに約4150万円ぐらいかかる。2人だと8300万円。 それを50歳までに貯める必要がある。
今までの計画では、40歳までは年間300万円、40~50歳までは年間400万円を貯金することで8000万円を用意する計画で、自分たちの老後の生活費はそれ以降に貯める計画だった。
老後の生活費については、平均的には27万円/月、ゆったりと生活するには35万円/月かかると言われている。 共働きで国民年金と厚生年金(生涯平均年収を650万円とする)がある場合にはそれだけで約35万円になるが、現時点でその額なので40~50年後少子高齢化が更に進んだ時に今想定している額がもらえる確率は低いと思っている。
想定の7割ぐらいもらえたとすると、ゆったり生活には毎月11万円不足し、年金をもらい始めてから35年間生きるには4620万円必要になる。 つまり、50~65歳の間も毎年300万円貯金して4500万円貯めることになる。
65歳まで仕事して100歳までギリギリ生きれる計算だが、これだと死ぬ間際は貯金も底を付いてしまいそうな状況になる。 いろいろ病気したらもっと早く貯金が尽きるかも…と思うと、結局70~75歳ぐらいまで働くことになるのか…と人生悲観していた。
ここまでが今までの考え方の話。
年末に少し投資の勉強をしていて、複利がこんなに素晴らしいものかと恥ずかしながら初めて気付いた。
(一旦様々なリスクの話を置いておいて)まずは単純化して話をすると S&P500 というアメリカの優良企業500社のインデックスファンドに投資しておけば、長期的には年率約10%の利回りで運用が可能なので、毎月5万円をコツコツ積立投資しておくと、30年で元本1800万円が1億円(9870万円)にもなってしまう。 60歳で1億円あれば、その資産の運用益だけで(税金20%引かれても)800万円/年が手に入ることになって余裕で生活ができる。
リスクヘッジのために株式だけではなくて、債権も買って〜となると年率10%で運用するのは難しいが、年率6%としても同様の条件で4700万円になる。(+5年すれば6700万円) 5000万円でも、運用益(6%)で税引き後240万円/年(=月20万円)ぐらいになるので、上の年金の計算での不足分11万円/月は十分に超えられる。 しかも5000万円の金融資産を残したままそれが実現できるので、大きな病気をしても安心感があるし、一応子どもにも資産を残して他界できる。
去年から確定拠出年金(iDeCo)を始めたのだけど、iDeCoの投資パターンがまるっきりこれと同じであることに気付いた。60歳まで投資金に手を付けられないのは、複利を効かせるために"手を付けさせないため"であることにやっと気付いた。 iDeCoを始める時には、23000円/月の積立で利率3%で見積もっていたので、30年運用しても元本828万円が1380万円程度にしかならず大した額ではないので、複利でもこんなもんかと思っていたのだった。
今回計算してみて気付いたが、これを始める時に大事なのは最初にいくら用意できるかだ。 0円からはじめて、月5万円、年率6%だとこんな資産推移になる。
1年目: 600000 2年目: 1236000 3年目: 1910160 4年目: 2624769 5年目: 3382255 6年目: 4185191 7年目: 5036302 8年目: 5938480 9年目: 6894789 10年目: 7908476 11年目: 8982985 12年目: 10121964 13年目: 11329282 14年目: 12609039 15年目: 13965581 16年目: 15403516 17年目: 16927727 18年目: 18543391 19年目: 20255995 20年目: 22071354 21年目: 23995636 22年目: 26035374 23年目: 28197496 24年目: 30489346 25年目: 32918707 26年目: 35493829 27年目: 38223459 28年目: 41116866 29年目: 44183878 30年目: 47434911 31年目: 50881006 32年目: 54533866 33年目: 58405898 34年目: 62510252 35年目: 66860867
最初の数年は積立金による増額が資産の増え幅の多くを占めていて、資産が大きくなってくると利率が効いてくることがよく分かる。 つまり例えば最初に600万円用意できれば、8年目終了時点からスタートできて、27年(35-8年)で6686万円にたどり着ける。 600万円スタートで、月5万円、利率6%とすると35年間で1億円に到達できる。
1年目: 6000000 2年目: 6960000 3年目: 7977600 4年目: 9056256 5年目: 10199631 (上の表を7年ずらしたのとほぼ同じなので省略) 26年目: 58669931 27年目: 62790127 28年目: 67157535 29年目: 71786987 30年目: 76694206 31年目: 81895858 32年目: 87409610 33年目: 93254186 34年目: 99449438 35年目: 106016404
最初に600万円増やすだけで35年後に4000万円の差が生まれるのである。(複利怖い)
少し話が逸れたが、結論は都内で6000万円ぐらいの家/マンションを買ってローンの頭金に600万円払うならそれを投資に使って、毎月5万円をきちんと積立していけば老後の生活費に不安は感じなくても良さそうということ。 そして年率10%で安定して成長するS&P500のインデックスファンドの存在を知れたことは大きかった。
年末年始にコード全く書いてないけど、コード書くよりも大事なことを勉強できた年末年始だった。
どこかのCTOが
プログラミングスクール通ってるかどうかとかどうでもよくて、 この年末年始にコード全く書いてない人はエンジニア向いてないんじゃないですかね、 それぐらい好奇心が必要な職業だとおもうけど
と言っていたので引用したかったが、すでにツイートが消されていて残念だ。
SRE本を読んだので概要をまとめてみた
2020年10月からSREになったので、そもそもSREとはどんな役割をもった職種なのか理解しないと行けないなと思って、Googleが出している Site Reliability Engineering (通称: SRE本) を読んでみた。
500ページもある厚い本なので、一人で読むのは途中で挫折しそうな感じがして、社内で輪読会を開いて読んでいくことにした。 毎週50ページぐらい読んでくるという少しハイペースで進めたが、2ヶ月半ぐらいかけて2020年末に無事全部読み終えることができた。 インフラは自分1人がメインで見ていて、サブで2人サポートしてくれるような体制なので、その3人+αで輪読会をして共通認識を得られたのはとても良かった。
2017年に出版された本だけれども、時代遅れな感じを受けることは全くなく、むしろ10年前からこんな運用してるGoogleすげーという感じで学ぶことばかりだった。 (Googleの自社自慢や社内話がところどころに散りばめられていて、Google SREの採用活動のために書かれた本 or 入社前のオンボーディング必読書として書かれた本なのでは?と思うことが多々あったが)
自分が読みながらまとめた概要を以下に書いていくので買おうか迷っている人はざっくり見てもらうと良いと思う。 全体を把握できるように丁寧に概要を書いたというよりは、自分がへぇ〜と思ったところをよく抽出しているので偏っている部分もあると思うがご了承頂きたい。
ちなみに、SREの役割・仕事内容についての理解を深めたいのであれば6章までの70ページぐらいを読めば十分であり、それ以降は自分の興味があるところだけかい摘んで読むのが効率が良い。 最初の70ページのためだけに5000円払うのでも価値がある内容である。
英語版は無料で公開されているので、英語ですらすら読める方はそちらをどうぞ。 (ちなみに社内輪読会でも普段技術書で英語を読み慣れているメンバーが英語版を読んでいたが、SRE本は技術書というよりは物語に近いので普段出てくる単語と傾向が違い大変だったと言っていた)
以下、章毎に概要。 (計2万字強あるのでまともに読むと大変だよ)
1章 イントロダクション
・昔は複雑なコンピューティングシステムを動作させるために、システム管理者(シスアド)を企業は雇ってきた。既存のソフトウェアコンポーネントを組み合わせてデプロイするような仕事。イベントに合わせて負荷対策をするのもシスアドの仕事。
・シスアド(運用, ops)は機能開発をするエンジニア(dev)とは異なるスキルセットが求められるので、devとopsという別のチームに分かれることになる。
・しかしそれが分けれていることで、コストがかかる。直接的なコストは複雑度や規模が上がるに従って、手作業で行っていてはそれに比例してチームを大きくしなければならないこと。間接的なコストはdevとopsで目標も使う言葉も異なることで、チームの間に溝が生まれてしまうこと。
・SREとはソフトウェアエンジニアに運用チームの設計を依頼したときに出来上がるもの。(従来は手作業で行っていた作業を自動化するもの)
・GoogleのSREの5~6割は一般的なGoogleのソフトウェアエンジニア。残りの4~5割は、Googleの一般的なソフトウェアエンジニアのスキルを85~99%しか持っていないが、シスアドとしての特別な知識を持っている人。(代表的な2つの知識はUNIXシステムの内部とL1~L3レイヤのネットワーキングについて)
・そのハイブリッドなチームにしたことで、今までのシスアドが手作業でやっていたものを自動化することができ、多様性により勝利した。
・チケット、オンコール、手作業といった「運用」にかかる時間を最大50%として、それらを自動化することを目的としている。
・SREの責任範囲は「サービスの可用性、レイテンシ、パフォーマンス、効率性、変更管理、モニタリング、緊急対応、キャパシティプランニング」。この責任範囲は本番環境に限らず、開発環境やテスト環境も含まれる。
・コーディングスキルを使う時間を最低50%は確保するために、超過した場合にはバグとチケットを開発チームに戻すことをする。オンコールに開発者をアサインしたりもする。50%を確保できるようになったらそのアサインはまたSREに戻す。
・これをすることで、開発者にも自動化をすることのインセンティブが働くようになる。
・Googleでは8~12時間のオンコールシフトの間に受け取るイベントは平均して最大2つ。それ以上あると振り返りができない。
・信頼性の目標として何%を目指せばよいのかは、以下を考えると良い。
・プロダクトの利用方法を踏まえて考えたとき、ユーザが満足する可用性のレベルはどの程度か
・プロダクトの可用性に満足できなかったユーザにとって、どのような代替策があるか
・可用性のレベルを変更したとして、ユーザのプロダクトの利用の仕方に何が起こるか。
・アラートはソフトウェアが解釈を行い、人間はアクションを行わなければならないときのみ通知を受け取るようにするべき。
・モニタリングの種類は以下の3つ。
・アラート: 人間が即座にアクションを起こして対応しなければいけないことが生じている、あるいは生じようとしていることを知らせる。
・チケット: 人間がアクションを起こさなければ修復できないが、数日かかったとしてもその結果障害が引き起こされることはないもの。
・ロギング: 人間が見る必要はないもの。何かが起きない限り誰かが読むことは想定されない。
・緊急対応に対して、手順書があると即興で行った場合に比べて3倍早く対応できることが知られている
・70%のサービス障害は動作中のシステムの変更によって引き起こされている。
2章 SREの観点から見た Googleのプロダクション環境
・以下用語整理。
・マシン: ハードウェアのことを指す。
・サーバー: サービスを実装しているソフトウェア (マシン上に構築)
・データセンターのマシンクラスタ内では頻繁にハードウェア障害が起きるので、それに影響を受けないように抽象化する必要がある。(Borg, k8s)
・Borgのジョブは再起動すればIPもportも変わるので、BNS(Borg Naming Service)で解決する
・利用できる平均のネットワーク帯域の最大化をソフトウェアで管理しているのがすごい
・ロックシステム(Chubby)とかモニタリングシステム(Borgmon)とか内製している。
・Googleの全てのサービスはStubbyというRPCを使って通信する。OSS化されているのはgRPC。
・GSLB(Global Software-Load Balancer)のロードバランサーがリバースプロキシ、フロントエンドサーバ、バックエンドサーバへのリクエストをすべてバランシングしている。(しかも単純なアルゴリズムではなくて、負荷が低いサーバーへリクエストを流している)
・アクセスのピーク + 2 台のpodがあることが望ましい。
・1つはローリングアップデート用。
・1つは障害が起きた場合。(2つ同時に起きる確率は極端に低いと考えられる)
・Writeの頻度が少なければGlobal Replicaは有効。
3章 原則
・トイル: 日常的に繰り返される運用上の作業で、永続的な価値を生み出さず、サービスの成長に比例してスケールするもの。
・可用性を向上させるとコストは比例ではなく、指数的に増えていく。信頼性を担保しながら開発速度を上げていくバランスが大事。
・可用性のターゲットレベルを決める要素
・ユーザが期待するサービスのレベル
・ユーザが直接的に(サービスのステイクホルダーに対しての)収入につながっているか
・サービスは有料か、無料か
・市場に競合がある場合、強豪が提供しているサービスのレベル
・サービスはコンシューマ向けか、企業向けか (企業向けは高めに設定)
・サービスのフェーズ (成長フェーズなら低めに設定)
・G SuiteのSLAは99.9%。SLOは必然的にもっと高い。
・エラーバジェットの形成方法
・PdMがQのSLOを規定する。
・稼働時間を計測する
・SLOと実際の稼働時間の差分(余剰)がエラーバジェットとなり、残っているのであれば新しいリリースをpushできる。
・エラーバジェットを使い切ってしまったのであれば、リリースは停止して、システムの弾力性を増したり、パフォーマンス改善、テストの追加をしたりする。
4章 サービスレベル目標
・SLIは本当に計測したい値とは異なる代替の値を使わないと行けないこともある。例えば、レイテンシは本当はクライアントサイドのものを計測したいが難しいので、サーバーサイドのレイテンシを代わりの値として使う。
・よく使われるのは可用性で、処理に成功した正常なリクエストの数の比率で計測される。
・最初から厳し目のSLOを定義するよりは、緩めに定義していって達成できたらあげていくほうが良い。
5章 トイルの撲滅
・トイルとは、手動で行う運用作業のこと。
・MTGやアラートの設定のクリーンアップなどはトイルではない、本番環境を動作させることに関連する作業で、繰り返し行われ、長期的な価値をもたないもの。
・トイルが多いと、キャリアの停滞やモラルの低下(不満の増大)などにつながる
6章 分散システムのモニタリング
・ホワイトボックスモニタリング: システムの内部によって公開されているメトリクスにもどつくモニタリング。
・ブラックボックスモニタリング: ユーザが目にする外部の振る舞いテスト。
・GoogleではSREチームの開発リソースの1割ぐらいをモニタリングシステムの構築とメンテナンスに使っている。
・モニタリングシステムは、「なにが壊れたのか」「なぜそれが壊れたのか」という2つの疑問にこたえられないといけない。
・4大シグナル (4つだけモニタリングできるとすればこれらを選ぶべき)
・レイテンシ
・トラフィック (リクエスト数)
・エラー (処理に失敗したエラーレート)
・サチュレーション (サービスの手一杯度。最も制約のあるサービスのメモリやCPUは十分か)
・モニタリングの仕組みは複雑にしすぎるとメンテナンスが難しくなるので、できるだけシンプルに保つように心がけること。
・無視されるアラートは本当に必要なのか考えるべき
・それほど重要ではないが気になるアラートはダッシュボードでモニタリングできるようにしておくと良いかもしれない。
7章 Googleにおける自動化の進化
・自動化のメリットは、時間が短縮されるだけではなくて、一貫性を保つことができることも上げられる。手作業によるオペレーションミスを防ぐことができる。
・自動化を進める上で、外部のベンダーに頼ってしまうとAPIが提供されていない場合があるので、できるだけ内製化を進めてきた。短期的にはコストになるが、長期的には資産(大きなメリット)になる。
・デプロイに関して言えば、PerlやChef,Puppetなどがある。全社は複雑な環境においてかゆいところまで手が届く。一方シンプルな構成であれば後者のほうが再利用しやすくエコシステムにも乗ることができる。
8章 リリースエンジニアリング
・リリースエンジニアの仕事
・理解が必要: ソースコード管理、コンパイラ、ビルド設定、自動ビルドツール、パッケージマネージャ、インストーラー
・スキルセット: 開発、設定管理、テストの統合、システム管理、カスタマーサポート
・リリースエンジニアはSWEと共にプロダクト開発を行いつつ、SREと共にリリースのステップを規定する。
・カナリアテスト、ロールバックなどもリリースエンジニアとSREが共同で戦略を考え構築する。
・リリースエンジニアリングの4大要素
・セフルサービスモデル: リリースが完全に自動化されていて、人間が手を出すのは問題があったときのみ。
・高速性: できる限り早くロールアウトできる必要がある。1時間ごとにビルドを行って、そのうちリリースするものを選択するチームもあれば、テストが通れば毎回そのままリリースするチームもある。
・密封ビルド: 1ヶ月前のバージョンであればその当時の環境でビルドされた結果が得られること。
・ポリシーと手順の強制: リリースに関する作業は行って良い人が決まっている。
9章 単純さ
・SREはソフトウェアの信頼性を高めるための手続き、プラクティス、ツールを作成するために働く。それと同時にこの作業がアジリティに与える影響を最小限に抑える必要がある。
・コード1行1行を負債と捉えることができるので、定期的にデッドコードを削除したり、肥大化したコードを検出する仕組みをあらゆるレベルのテストに組み込むようにする。(小さなアプリケーションはバグりにくい)
・リリースも小さい(単純)な方が何が影響してデグレしたのか原因がつかみやすいし、APIも単純な方が(影響範囲が小さくて)バグりにくいし、修正も早く行える。
第三部 実践
サービスの信頼性の階層
基礎から順に
1. モニタリング
2. インシデント対応
3. ポストモーテム/根本原因分析
4. テスト及びリリース手順
5. キャパシティプランニング
6. 開発
7. プロダクト
モニタリングがされていなければ。視界を閉ざされたまま飛行しているようなもの。
10章 時系列データからの実践的なアラート
・Borg(2005年)のモニタリングサービスとしてBorgmonが生まれた。
・Borgmonの設計思想は今のPrometheusにかなり近い。
・アラートのためにデータソースとして時系列データを使うというのはBorgmonから始まり、最近のOSSの監視ツールの標準になってきた。
・Bogrmonのログ収集の設計はDatadogのログ収集構成と似ている感じがする。
・各podにscraperがいて、クラスタ単位で集約して、グローバルBorgmonに飛ばす
・Borgmonで監視できるのはホワイトボックステスト(内部からの視点)だけなので、外部からの監視(ブラックボックステスト)もやる必要がある
・モニタリングのメンテナンスコストがサービスのサイズに比例しないように設計していくことが大事
11章 オンコール対応
・理想のレスポンスタイムは、時間に対する要求が厳しいサービスであれば5分、そうでないものは30分以内に対応するのが望ましい。
・オンコールチームは、プライマリとセカンダリのローテーションを用意して、プライマリが見過ごしたものはセカンダリが対応する。
・マネージャーはオンコールの量と質でメンバーのバランスを取る必要がある
・量: ローテーションの時間
・質: 対応したインシデントの数
・業務全体の50%以上はエンジニアリングに。オンコールは残りの時間の25%以上にならないようにする。
・つまり、プライマリとセカンダリで1人ずつ用意するためには最低8人のエンジニアが必要。
・根本原因の分析、改善、ポストモーテムの執筆、バグの修正までやると1件あたり平均6時間かかる。つまり12時間のシフトで2件の対応が限界。
・過負荷にならないためにはシフト中の発生数の中央値は0であるべき。
・時間外のオンコールには適切な補償を検討すべき。
・困難に直面した時、近年の研究の結果人間は反射的に行動する場合と理性的に慎重に行動する場合と2パターンに分かれることが分かっているが後者の行動をすべき。
・経験則に頼るのは良くない。4つの障害のうち最初の3つが外部サービスによる障害だったら、4つめも何も見ずに同じ障害だと考えてしまいがち。
・アラートはSLOを脅かす症状に対して行うべき。
12章 効果的なトラブルシューティング
・物事がうまくいく場合といのは、おかしくなる場合の中の特殊な例の一つ。
・問題があった場合には直接誰かに伝えるのではなく、皆が見える場所にチケットとして残しておく。それはあとから参照できるようにするため。
・問題を知っている少数のメンバーで対応して負荷が集中することになってしまう。
・トラブルシューティングでは最初に根本原因を突き止めたくなるがその動きは良くない。重要なのは被害をそれ以上に広げないこと。
・システムがその環境下ができるだけうまく動作するようにすること。例えば、まだ生きているクラスタへトラフィックを流す、一部のリクエストをドロップして負荷を下げるなど。
・場合によってはシステムをすべでダウンさせることも被害を広げないためには必要。
・否定的なデータは価値がある。(同時コネクション800以上にするとエラーが出たなど。)こういうものは積極的に外部に公開していくことで、他の人が同じ実験をしなくてもよくなる。
・特に意外だと思った結果ほど他の人にとっては価値のあるものになる
13章 緊急対応
・プロダクション環境のバックアップアクセスを持つ専用のセキュアルーム(パニックルーム)があり、必要に応じてそこに集まる。
・Googleは社内システムにも自社サービスを使っているので、それが落ちると社内でもコミュニケーションが取れなくなる。
・自動処理のバグによって一気に全台に悪影響が広がってしまうこともある。オートメーションは停止でき、人間による手作業でも操作できるように設計しておく必要がある。
・インシデントを起こした人が一番状況が分かっているはずなので、その人に協力してもらうことは大事。
・同じことを二度と起こさないために、過去に何が壊れたのかをきちんと記録しておく。
・ポストモーテムで書いた改善点は確実に行うこと。
・大きな、むしろありそうもないような問いかけをしてみよう。主要なサーバーセンターが突然沈黙したら、だれかがDDoSを仕掛けてきたら…
14章 インシデント管理
・インシデントの状況をみたメンバー各々が、各自で思いついたアイデアを本番に適用していては何をして事態が改善した/悪化したのかわからない。きちんとコミュニケーションを取ることが必要。
・インシデント時はきちんと役割分担をして、他人の領域に踏み込んでしまわないことが大事。
・役割一覧
・インシデント指揮者: インシデントに対する高レベルな状況把握をする。事実上移譲していないすべての役割を担う。
・実行作業: システムを修正するのは実行作業チームのみ。
・コミュニケーション: ステークホルダーに対して定期的に最新情報を発行する。ドキュメントを正確かつ最新の状態に保つことまで受け持つ場合もある。
・計画者: 長期的な課題を扱うことで実行チームを支援する。バグの登録、夕食の発注、引き継ぎの調整など。
・インシデントが発生したときに集まる部屋があることが大事。遠隔チームであればIRC(Slack)を使うと記録が残って良い。
・複数人が同時に編集できるライブドキュメントがあるとよい。GoogleではGoogle Docsを使っている。
・付録Cにテンプレートがある
・ベストプラクティスまとめ P.173
15章 ポストモーテムの文化: 失敗からの学び
・ポストモーテムを書く目的は、インシデントがドキュメント化されること、影響を及ぼした根本原因が十分に理解されること、再発の可能性や影響を削減するための効果的な予防策が確実に導入されるようにすること。
・ポストモーテムを作成するかどうかは以下のような基準で判断される。
・ユーザに影響を及ぼしたダウンタイムが一定のしきい値を超えた場合
・データの損失が生じた場合
・オンコールエンジニアの介入が必要だった場合
・解決までの時間が一定のしきい値を超えた場合
・モニタリングの障害 (人手でインシデントが発見された場合)
・事前にポストモーテム作成の基準を明確にしておくと良い。
・ポストモーテムにおいて大事なことは、インシデントに関わりを持ったすべての人が知り得た情報をもとに善意でとった行動であるという前提で、人に対して批判をしないこと。
・ポストモーテムのテンプレート: 添付D
・ポストモーテムを書く文化を根付かせるために、過去のポストモーテムを振り返るポストモーテム読書会をやったり、過去のポストモーテムをロールプレイする不運の輪をやったりするとよい。(楽しい軽食と共に)
16章 サービスの障害の追跡
・Googleにはサービス障害のログを残す Outalator という社内サービスがある。
・この四半期におけるアクション可能アラートと不可能アラートの比率を集計したり、メンバーごとの対応オンコール数の集計などができたりする。(アラートのエスカレーションの仕組みも入っていたりする)
・1つのインシデントが複数箇所に影響を及ぼす場合、それぞれのチームに独立してアラートが行くのは効率が悪いため、それらは1つの原因によって起きているというグルーピングをしたい。
・アラートが偽陽性の場合もあるので、ラベルを付与できるようになっている。
17章 信頼性のためのテスト
・ユニットテスト: テスト駆動開発の概念を取り入れるために使う
・システムテスト: デプロイされていないシステムに対してエンジニアが実行するテストとしては最大規模のもの。エンドツーエンドでテストする。
・スモークテスト: 単純で重要な挙動をエンジニアが確認する
・パフォーマンステスト
・回帰テスト: 過去に起きたバグのテストケースたち
・本番環境に対するテスト
・設定テスト
・ストレステスト: データベースはどこまでいっぱいになると書き込みに失敗するか。
・カナリアテスト
18章 SREによるソフトウェアエンジニアリング
・GoogleのソフトウェアといえばGoogle MapやBigTableのようなものを思い浮かべるが、社内向けのツール(ソフトウェア)もたくさんある。とても複雑なProduction環境なので一般的なツールではカバーできないことが多く、自分たちで作る。
・インテントベースのキャパシティプランニング。やりたいこと(サーバーをN台欲しい)を抽象化していくと、最後には99.999%の信頼性で動作させたいという要求になる。一般的には「XのリージョンでN+2の冗長性を確保したい」という粒度のインテントベースのプランニングをする(Googleの最低基準がここ)が、より洗練させたければ、可用性でしていできるようにするとよいだろう。
・Auxonはキャパシティプランニングの自動化ツール。インテントベースで要求ができる。例えば、「フロントエンドサーバはバックエンドサーバから50ms以内でなければならない」「大陸ごとにN+2でなければならない」という要求ができ、優先順位をつけられる。
・Auxonを作ったチームはもともとスプレッドシートでキャパシティプランニングを行っていたが、自動化の余地があると思って作った。最初はヒューリスティックなロジックだったが、そのロジック部分は後から入れ替え可能なように作られており、本番で稼働させながら改善をさせて、最終的に線形計画モデルを使ったものになった。
・いきなり完璧なツールができた!と社内に持っていくと上手く動かなかった時に信頼を失うことになるので、きちんと期待値の調整をして導入する必要がある。
・Googleの社内ツールプロジェクトは、空いた時間で開発される草の根作業のままにしてもよいし、構造化されたプロセスを通して正式なプロジェクトにすることもできる。
19章 フロントエンドにおけるロードバランシング
・サービスによって、適切なロードバランシングのアルゴリズムが異なる。例えば検索サービスであればすぐに結果が欲しいのでレイテンシが小さいことが大事、動画のアップロードであれば、すぐに終わることは期待していなくて1度で成功して欲しいのでレイテンシを犠牲にしてもスループットが出せる利用率の低いリンクが適している。
・一番前段でバランシングするのはDNSのロードバランス。Aレコードを複数返すことでクライアントはそこから1つを選んでリクエストしてくれる。理論的にはSRVレコードを使ってレコードの重みや優先順位を付けられるが、まだHTTPには採用されていない。
・権威DNSサーバーが最適なロードバランシングをしても、ISPのネームサーバーはTTLの期限内であればその結果をキャッシュするので、多くのユーザはそちら(キャッシュ)を使ってしまう。(Googleは自前で大規模なDNSリゾルバ群を持っているのでできる?)
・仮想IPアドレス(VIP)でのロードバランシング。VIPの実装で一番大事なのはネットワークロードバランサー。
・L2でバランシングする、つまりパケット送信先のMACアドレスのみを変更することにより、バックエンドはオリジナルの送信元と送信先IPを受け取れるので、バックエンドは直接オリジナルの送信元に送信できる(ダイレクトサーバーレスポンス, DSR)
・しかしこれには問題があり、すべてのバックエンドのマシンがお互いにデータリンク層(L2)で到達可能である必要がある。(Googleの場合にはネットワークがこれをサポートできなくなり、マシン数が単一のブロードキャストドメインに収まらなくなった)
・その解決策はP.239
20章 データセンターでのロードバランシング
・処理を行う個々のサーバーにリクエストをルーティングするためのアプリケーションレベルのポリシーを取り上げる。
・クライアントが、バックエンドの負荷状況を追えているとして、空いているバックエンドにリクエストを投げるロードバランスはうまくいかない。(説明がよくわからず P.244)
・クライアントから見ると、バックエンドは以下の3状態がある。
・健全: リクエストを処理している
・接続拒否: 起動中やシャットダウン中など
・レイムダック: リスニングしており処理もできるが、リクエストの送信をやめるように明示的に要求している
・レイムダックのメリットは、グレースフルシャットダウンができること。
・クライアントとバックエンド間のヘルスチェックはクラスタのサイズがでかくなってくると一気にコストが高くなる。そこで20~100ぐらいのバックエンドのサブセットを用意することが多い。
・クライアントは使えるサブセットを使うか決まっている。
・1つのバックエンドにリクエストが集中しすぎて過負荷になると、別のバックエンドにつなぎに行くときにTCPのオーバーヘッドが発生する(通常は一度コネクションを張ったまま張りっぱなし)。 そのオーバーヘッドが原因でそのバックエンドも過負荷になってしまう。
・(こういうアルゴリズムを考えたがうまくいかなかった。という話が多い)
・ランダムに接続先のサブセットを選ぶのでは、負荷の偏りが大きい。
・決定的なサブセット選択のアルゴリズムを使うと300クライアント300バックエンドで、きれいに均等に分けることができる。
21章 過負荷への対応
・Googleでは高負荷な状態では、検索対象のコーパスを減らしたり、完全に最新ではない可能性があるオーかるのコピー(キャッシュ)を使うことで負荷を減らして、1リクエストあたりの負荷を下げるようになっている
・バックエンドが過負荷のエラーを返すと、フロントエンドは自主規制をするようになっており、その上限をこえるリクエストはローカルで失敗させて、ネットワークに出ていかないようにする。
・リクエストの重要度を4段階に分けていて、上の2つはユーザに影響がでるのでその範囲では確実に処理ができるようにプロビジョニングしておく必要がある。
・重要度の低いものは過負荷な状態では拒否される
・その重要度はリクエストがいくつかのバックエンドサーバーを経由する場合でも伝搬される。
・エグゼキュータ平均負荷: プロセス中のアクティブなスレッド数を数えて、その値を指数関数的減衰で平滑化する。これによってファンアウトを持つリクエスト(短時間高負荷なもの)を受信するとスパイクが発生するが、平滑化によってほぼ飲み込むことができる、それが長時間になる場合には拒否をする。
・リトライは3回まで実行して、それでもだめならリクエスト元にエラーを返す。(データセンター全体が過負荷と判断する)
・リクエスト側にもリトライバジェットが設定されていて、全体のリクエストの10%がリクエストならOK。これはデータセンターにまだ余裕があれば10%以内に収まるという根拠で設定。
・過負荷に陥ったバックエンドはシャットダウンするというのはよく聞く考えだが、正しくなくきちんとロードバランサーがそこへのリクエストを遮断してあげるのが正しい選択。
22章 カスケード障害への対応
・カスケード障害とは、ポジティブフィードバックの結果として、時間と共に拡大していく障害のこと。
・1つのレプリカの負荷が高くなると、残りのレプリカの負荷も高まり、ドミノ式に全レプリカがダウンしてしまうやつのこと。
・CPUの高負荷やメモリの消費量増大で起きる影響まとめ P.276
・CPUの利用率が増えると、キャッシュヒット率も減ってCPU利用効率が下がる。
・処理するリクエスト数が増えるとメモリの消費量も増えてキャッシュヒット率が下がって更にバックエンドへのリクエストが増えたりする。
23章 クリティカルな状態の管理: 信頼性のための分散合意
・対障害性を高めるために通常は複数拠点にまたがってシステムを動作させるが、それらを正しく動作させるためには分散合意が必要。
・CAP定理とは、以下の3つの性質は同時に満たすことができないというもの。
・各ノードにあるデータの一貫したビュー
・各ノードのデータの可用性
・ネットワーク分断への耐性
・伝統的なACID(原始星、一貫性、独立性、永続性)から、次第に増えつつ得る分散データストアの特性BASE(高い可用性、厳密ではないステータス、結果整合性)に変わってきている。
・BASE特性をサポートするシステムの多くは、複数のマスターレプリケーションに依存していて、書き込みが並列で行われる。その衝突を回避するための仕組みを持っている。例えば、タイムスタンプが新しいものを優先するというようなシンプルなもの。それは "結果整合性" と呼ばれる。
・しかしこれは時として驚くような結果を及ぼすことがあって、クロックのゆらぎやネットワークの分断が起きたときに生じる
・複数のマシン間で時計が同期していることを保証するのは不可能
・結果整合性を持ったデータストアを扱うのは開発者にとっては難しく、エラーの起きやすい複雑な仕組みを構築してしまっていた。(これは本来データベースのレイヤで解決されるべき問題)
・うまく行かないアルゴリズムの例が3つ書かれている。(P.304)
・それらの問題を解決するプロトコルはいくつかあり、その一つがPaxosプロトコル。
・分散合意アルゴリズムをうまく利用しているシステムの多くは、それらのアルゴリズムを実装しているZooKeeper、Consul、etcd といったサービスのクライアントとして動作している。
・SolrもバックエンドにZooKeeperを使っている
・RMS (Replicated State Machine) は同一の処理の集合を同一順序で複数のプロセスで実行するシステム。
・分散処理のバリア(ロック, 他の処理が終わるまで待機)や、キューをRSMとして実装すればシステム全体を遥かに頑健なものにできる。
・分散合意のパフォーマンスについて、Googleでは一番大きなボトルネックは大陸をまたぐような場合のレイテンシで、リーダープロセスが別の大陸にあるとそこへの通信の往復(ラウンドトリップタイム)によりパフォーマンスが劣化してしまう。(アルゴリズム自体はボトルネックではないらしい)
・まとめ。分散システムを使うときにハートビートのようなアルゴリズムで手当たり次第に作るのは良くないよ。
24章 Cronによる分散定期スケジューリング
・cronの実行を小規模で行う場合と大規模で行う場合の違いについて。
・cronジョブには冪等性があるもの(GCのように何度実行しても大丈夫なもの)と、メール送信のように2回以上実行してはいけないものなどがある。(1度スキップされてよいものとそうでないものもある)
・二重起動してしまうよりも、スキップされる方がリカバリしやすい。そのため、問題があったときには「フェイルクローズ」状態になるように設計するのが大事。
・Googleでは分散cronをしていて、Fast Paxosのプロトコルで分散cronを管理している、プライマリが途中で死んだ場合には、セカンダリがプライマリになってその処理を引き継いで途中から実行する。(このフェイルオーバーは1分以内に完了する)
・cronは大規模に実行すると実行時間の偏りでスパイクが起きやすいので、実行しても良い時間の範囲を指定できるようにした ( 0..23 のように)
25章 データ処理のパイプライン
・ビッグデータを処理するための定期的なパイプラインに対する、信頼性とスケーラビリティに優れた代替案として、リーダー - フォロアーモデルの新たな見方を紹介。
・旧来のcronのような定期実行でデータを処理するやり方は データパイプライン と呼ばれる。
・ビッグデータに対して、1つの出力が次の入力になってつながっていくものを マルチフェーズパイプライン と呼ぶ。(パイプラインの数を 深さ と呼ぶ。)
・深いパイプラインは深さ数十から数百になる。
26章 データの完全性: What You Read Is What You Wrote
・Q.データの完全性とは? A.データがユーザから利用可能であり続けること
・G Suiteを運用してきて24時間以上データにアクセスできないと信頼に大きく関わることが分かってきた。
・データが一部破損していてそれが復旧不可能であれば、そのユーザへの稼働時間はその間失われていることになる。
・データの完全性を極めて高くすることの秘密は、予防的な検出と素早い修復。
・アーカイブは監査や法的証拠開示に基づいた過去データの取り出し、コンプライアンスを目的として長期に渡ってデータを安全に保管すること。これは短時間でリカバリできないといけないバックアップとは違う要求。
・データが長期間見えないのであれば、完全性が保たれていようと、そのデータは存在しないも同然
・障害におけるデータの可用性に対してSLOを定義して、それを満たせるかどうかを実践しておくことが大事。
・障害の種類は以下の組み合わせて24種類ある。
・根本原因: 6種類(P.365)
・範囲: 2種類 (広範囲、狭く直接的)
・レート: 2種類(ビッグバン、ゆっくり着実)
・ゆっくり進むデータの損失に対しては、特定の時間に戻ってデータを抽出してくる必要があり、ポイントインタイムリカバリと呼ばれる。
・ACIDやBASE特性をもつデータストアにこの機能をもたせるのは今日では幻想なので、自分たちでバックアップをとってやるしかない。(パフォーマンス的に無理)
・レプリケーションはバックアップにはならない。
・リテンションとはデータのコピーを起こしておく期間のこと。徐々にデータが失われていったときに、その期間まではリストアすることができる。
・ユーザが操作を誤って削除してしまったときには自身でロールバックできれば障害にならない (Driveで30日後に完全に消えるみたいなやつ)
・し、サポートの負担をかなり減らすことができる
・APIを提供する場合でも、ユーザからは見えないけど裏側で論理削除しておき、数日後に物理削除するような設計ができる。
・バックアップの期間はGoogleは30~90日(サービス毎に異なる)としている、それ以上取っておいてもデータの構造が変わっていたりと復元がかなり困難になることが多い。
・データサイズがTBからEB(エクサバイト)になると同じ戦略では通用しなくなるので注意
・インクリメンタルバックアップをとっておき、それを並列に実行できるようにシャーディングしておくことでリストアにかかる時間を1/Nにすることができる。
・Googleで過去にあった大規模障害の例 2つ (GMailとGoogle Music)
・テープからのデータ復元方法について、大規模な場合にはベンダーが用意しているロボットでの復元よりも、手作業でやるほうが数百倍早いことが練習で分かっていた
・複雑なシステムの場合には完全には理解しきれないバグを持っているものなので、どれほど経験を積んでいても障害を起こさないことは不可能に近い。そのため多重防御の実践は大事。(オンラインのバックアップとテープをオフラインバックアップとして持っておくことなど)
27章 大規模なプロダクトのローンチにおける信頼性
・Googleではローンチ調整エンジニア(Launch Coordination Engineers, LCE)から構成される専用のチームを立ち上げて、ローンチを成功させるためにエンジニアリングチームに助言を行うようにした。
・ソフトウェアエンジニアやシステムエンジニアや、SRE出身の人がいる
・ローンチの定義は、アプリケーションに対して外部から目に見える変更を行う新しいコードがあること。
・Googleでは週70回ローンチしている。
・ローンチ調整エンジニアの役割
・ローンチに関わる複数チームの連絡役
・タスクが滞りなく進んでいることを確認して、技術面からローンチを推進する
・門番の役割を果たし、ローンチが安全だという判断の承認を行う
・開発者に対してベストプラクティスやGoogleのサービスと統合する方法について教育するためにドキュメントやトレーニング用のリソースを準備する
・Googleの場合LCEにするとほとんどのプロダクトのチームに関われるので社内全体がわかる!
4部 管理
・単独で働くSREは存在しないので、チームで働くことについて取り上げる。
・複雑で変化の早い環境における考え方を採用直後の数週間から数ヶ月のうちにトレーニングすることでベストプラクティスを学ぶ。これがないと習熟に数年かかることもある。
・SREの採用はGoogle全体の標準に照らし合わせてさえ候補者を見いだしにくいし、効率的に面接することは更に難しい。
28章 SREの成長を加速する方法: 新人からオンコール担当、そしてその先へ
・新しく入社したSREをどう成長させていくかという話。
・表28-1にSREの教育方法の推奨パターンとアンチパターンがある。
・図28-1に入社直後からタイムラインでどんな学習をしていくべきかが整理されている
・こういったものは時間経過に伴い古くなっていくが、意図的に古いものを1,2つ混ぜておいて、オンボーディング終了後にそれを改訂する課題を課す。
・オンコール担当ができるようになったら新人SREは卒業で、そこからは自らが継続的に学習をしていく必要がある
・OJTでいきなり「みなと一緒にやってみよう!最初は大変だけどそのうち慣れれば早くできるようになるし、ツールもだんだんと分かってくるよ!」とするのはよくある一般的な新入社員への対応だが、これはベストではなく、より良い方法がある。
・それをしてしまうと以下のような疑問を抱いてしまう
・私はなんの作業をしているのだろう?
・私はどれだけ前進できているのだろう?
・学習の仕組みにはある程度の順序をもたせ、目の前の道筋がみえるようにする必要がある。
・P.416 にオンコール学習チェックリストがあり、オンコール担当になるまでに必要なものがまとめられている。これがあることで、自分のやっていることがどこに当てはまるものなのか、どれぐらい自分が理解できているのかを把握することができる。
・メンターがチェックリストに対する回答をチェックし、問題なければ次のステップに進む。
・ステップが進むに従って、触れるインフラの権限が増えていく。最初はすべてリードオンリーで徐々に書き込み権限が与えられていく。
・学習プログラムとプロジェクト(実際の仕事)の両方に関わるべきで、それにより目的と生産性の間隔を養うことができる。Googleのインフラを一通り理解するための初心者向けプロジェクトが渡される。
・プロジェクトの例:
・ユーザが使う機能に手を入れて、それを本番環境までリリースする。これにより開発者への共感が養われる。
・サービスで盲点になっているところにモニタリングを追加する。(同時に現状の課題認識もできる)
・まだ自動化されていない運用上の課題を自動化する
・Googleでは今までの仕事の中で見たいことのないシステムにであうので、すぐれたリバースエンジニアリングのスキルを持っている必要がある。大規模な環境では検出が難しい異常が発生するので、手続き的よりは統計的に考える能力が必要になる。また、標準的な運用手順が破綻した場合には、完全に臨機応変に行動できなければならない。
・障害が発生したとき、取りうる選択肢は何百もあるなかで、それを選択するのか目の前に広がる決定木を効率よく刈り込んでいく必要がある。これは経験によってより高速にできるようになる。分析と比較をうまく行うことが大事。
・泥沼化する障害対応によくありがちなのは、未検証の推定を多く取り入れてしまうこと。そういうときは一度ズームアウトしてさまざまなアプローチを取ってみるということはSREが早い段階で学ぶべき教訓の一つ。
・サービスのトラフィックをすべて追いかけて、ユーザのクエリがたどる経路をたどっていく新人向けの課題がある、その構成図をシニアSREに見せるとシニアSREも知らない最近の変化を知ることができる。
・ポストモーテムはまだ入社していない新人が読むことを想定して書くと良いし、価値あるポストモーテムとは新人の教育にも使えるものである。
・ディザスターロールプレイング: 週1のMTGで犠牲者を1人選び、その人は過去に起きた障害の解決をしないといけない。犠牲者は起きた問題に対してどう行動するかを伝え、司会者はそれに対して実際に起きたことを伝える。
・過去に起きた忘れられていそうな障害や、近くリリース予定のものに関連して起きそうな障害を題材とするとよい
・サービスのここに損傷を与えた場合、どのメトリクスがどう変わるかを事前にチームで話し合う。それを実際にやってみて、予想通りにメトリクスが動いたかどうかを観察する。という学習方法をQ毎に実施している。(「検索クラスタを焼き払おう」という名前が付いている。謎)
・新人SREはシャドウオンコール担当として、シニアSREのオンコール対応を横で見守ることでどう対応しているのか学ぶことができる。次のステップは逆シャドウで、シニアに後ろに付いてもらってアドバイスを受けながら実際のオンコール担当をする。
29章 割り込みへの対処
・運用負荷には大きく3種類あり、ページ、チケット、運用業務に分類できる。
・ページは本番環境で非常事態が生じると発せられる。単純作業なものから思考が必要がものまであるが、期待されるレスポンスタイム(SLO)があり、分単位で設定されるものもある。ページの管理はプライマリオンコールエンジニアが対応する。
・チケットは顧客からの要望で、簡単なチケットであれば設定を変更して1回コードレビューを受ければ良いものもあるし、複雑なものは設計やキャパシティプランニングの変更などがある。チケットにもレスポンスタイム(SLO)が定められる事があり、単位は時間、日、週ぐらい。チケットの管理はプライマリオンコールエンジニアのスキマ時間に行ったり、セカンダリオンコールエンジニアが担当したり、オンコールエンジニア以外のエンジニアが担当したりとチームによって異なる。
・運用業務(トイル)は、コードやフラグのロールアウト、顧客からの単純な質問への回答が含まれる。管理方法はチケットと同様で様々。
・フロー状態(ゾーン)に入ることによって、生産性が増すだけではなく芸術的な創造性や科学的な創造性も増す。割り込みによってここからはじき出されないように、できるだけ長時間この状態にいれるようにすることが大事。
・フロー状態に到達するための最も明確な道筋の一つは、やり方がわかっているタスクを処理すること。
・プロジェクトとオンコールが共存する環境ではそのバランスが重要で、理想のバランスには個人差がある。
・オンコールのローテーションが長いと、根本解決をしようという判断をしにくく、同じ問題でうんざりさせられる人が続き、身動きが取れなくなってしまうことがある。チケットもオンコールと同様に引き継ぎを行って解決に時間がかかる問題にも取り組んでいく必要がある。
30章 SREの投入による運用過負荷からのリカバリ
・GoogleのSREチームでは、プロジェクトと対処的な運用業務(デバッグ、トラブルシューティング、オンコール)に均等に時間を割り振ることが標準的なポリシーとなっているが、大量のチケットにより数ヶ月に渡ってバランスが崩れることがある。これが継続すると燃え尽き症候群になったり、スケールする仕組みを作れなくなる。
・解決のためには別のチームからSREを連れてくる。タスクをさばくだけではなく、プラクティスの改善に焦点を当てる。特に1章(プラクティス、哲学)や6章(モニタリング)の部分は重要。
・以下はチームにプラクティスを提供するコンサルティングとして参画する方へのアドバイス。
・フェーズ1: サービスの学習と状況の把握
・スケール仕組みを作れているか、そういう思想になっているかが大事。そうでない場合を "運用モード" と呼ぶ。非常事態の数をへらすのではなくて、非常事態に素早く対応する方法に焦点を当ててしまうことによって運用モードに陥りやすくなる。(足りないなら単純に増やせばいいじゃん、自動化せずに。と考えてしまっている)
・フェーズ2: 状況の共有
・ポストモーテムを有効活用して、チームが学習していける基礎を作る。ポストモーテムがうまく書けないと誰かを非難してしまったり、次への教訓にならないポストモーテムが出来上がってしまう。
・フェーズ3: 変化の推進
・まずは基礎から固めていく。SLOがないならそれを定める。SLOが重要なのはそれによってサービス障害のインパクトを定量的に計ることができるようになるから。
・コンサルタントがチームを離れた後でも、チームメンバーが彼ならどうコメントするだろうとうまく予想できるようになっている必要がある。うまいコメントの例は
・リリースを延期したのはテストに問題があったわけではありません。リリースに対して設定されたエラーバジェットが尽きてしまっているからです。
・SLOが厳しいので、リリースは問題なくロールバックできる必要があり、リカバリに要する平均時間は短くなければいけません。
・導く質問をすること。良い例と悪い例
・Good) TaskFailures アラートが頻繁に発生しているが、対応していません。これはSLOにどう影響していますか?
・Good) このターンアップの手順は相当複雑に見えます。新しいインスタンスを立ち上げるのになぜこれだけ多くの設定ファイルを更新しなければいけないのか理由は分かっていますか?
・Bad) これらの古くて停止したままのリソースたちは、どうしたんですか?
・Bad) どうしてFrobnitzerはこんなにたくさんのことをやっているんですか?
・最後にコンサルタントがチームを離れるときには、教えたことをチームが確実に実践するためのアクションアイテムを作ると良い。それを報告書としてまとめたものがポストバイタム(ポストモーテムの反意語)
31章 SREにおけるコミュニケーションとコラボレーション
・SREチームにも多様性があり、インフラチーム、サービスチーム、プロダクト横断なチームをもっている。たまには開発チームになることもある。
・開発チームとの関係は、SREチームと同規模の場合もあるし、何倍にも大きい規模の場合もある。
・プロダクションミーティング: SREチームが担当するサービスの状況について毎週30~60分で説明する。サービスの運用パフォーマンスの詳細について話し合い、それを設計や設定、実装と関連付けて考え、問題解決の方法を推奨するもの。設計上の判断をサービスのパフォーマンスと合わせて考えることは極めて強力なフィードバックループになる。
・遠隔で2チームの会議をする場合、人数が少ない方のチームのだれかにファシリテーターをやってもらうと、大人数のチームが自然と少人数のチームに耳を傾けることになって上手くいくことが多い。(科学的根拠はないけど経験的に)
・プロダクションミーティングのアジェンダ
・予定されている変更の確認
・メトリクス (最近の傾向、負荷の状態など)
・障害 (ポストモーテムが書かれる規模の障害について)
・ページされたイベント (ページのされ方は適切だったか、それはページされるべきだったのかの2点について)
・ページされなかったイベント (ページされるべきだったけどされなかったもの、ページすべきでないものの注意を引く必要があるもの)
・これまでのアクションアイテム (前回決めたアクションができているのか)
・既存サービスの大規模データマイグレーションは(Googleでも)よく発生する
32章 進化するSREのエンゲージメントモデル
・サービスが最初からSREのサポート対象になるわけではない。サービスを評価して、SREがサポートするに値するかどうかが判断される。
・SREが関わる最初のプロセスはPRR (Production Readiness Review)。プロダクション環境におけるサービスの信頼性を評価する。サポートを受けるにはこれが必要。
・SREのサポートが受けられない場合でも、ドキュメンテーションやコンサルティングなどは提供されている。コンサルティングの場合にはSRE1,2人が数時間をかけてレビューしてフィードバックをする。
・基本的にはPRRをしたSREがそのサービスのサポート担当になる。最初は開発チームと一緒にインストラクションを行うが、この関係はその後に続くチーム関係の基盤となる。
・サービスの設計フェーズからSREが関わることでより理想の設計に近づけた形で開発をスタートすることができる。
・PRRは2~3Qぐらいかかることが多く、またレビューを希望しているサービスも多いので、レビュー対象のサービスの優先順位付けも厳密に行われることになった。
・SREの人数の増加がサービスの数の増加に追いついていない状態。SREを採用できてもトレーニングは通常よりも長い期間のトレーニングになる。
・その結果、ベストプラクティスをフレームワーク化していく方向に解決策を見出した。プロダクション環境で適切に動作するものをコードとして用意しておき、サービスはそれを利用するだけで、設計レベルからProduction Readyになる。
・フレームワークを使うことで、PRRのレビューコストも下がるし、フレームワーク向けに作られたツールはSREがいなくてもすべて使用することができる。
5部 まとめ
33章 他の業界からの教訓
・ライフセーバーを10年やっていた人が今GoogleでSREをやっている。信頼性という意味でこういうバックグラウンドは大事。
・障害への対策として、他の業界でもシミュレーションや実地訓練を主要な焦点としている。
・航空業界では実地訓練はできないのでリアルなシミュレータに実際のデータを流し込んでいる。
・ポストモーテムも業界によって呼び方は違うが、どこでも同じようなことは行っている。
・反復作業は自動化しようというのがソフトウェアエンジニアには根付いている文化であるが、業界によって例外もある。原子力海軍は自動化は行わず、手動で作業をしている。自動化やコンピュータはあまりにも高速すぎるので大規模で回復不可能なミスを犯すことを懸念している。原子炉を扱う場合にはタスクをすばやく終わらせるよりもゆっくりとした安定的なアプローチを取ることの方がはるかに重要。
・Googleが扱っているのは、なにか問題があっても直接的に命に関わるようなことはない分野。それを意識してエラーバジェットのようなツールをイノベーションの文化や、計算下でリスクを犯すための資金として有効に使うべき。
34章 まとめ
・Googleでは1000人を超えるSREが10箇所のサイトで働いている。
・100年前の飛行機が操縦士1人に対して、積み荷がいくつかしかなく、自分でメンテナンスも行っていた。それが現在はパイロット2人で6000マイルも飛行して乗客も百人単位で載せることができる。SREもこれを目指さないといけない。
・SREチームはできるだけコンパクトであるべきであり、高レベルでの抽象化とフェールセーフとしての多くのバックアップシステムと、考え抜かれたAPIが拠り所になる。同時に、日々の運用から得られるシステムに関する包括的な知識も併せ持つ必要がある。